When doing maintenance on a SQL Server there are number of things that must be completed. These include backups, index optimization, DBCC Checkdb and update statistics. This post really isn’t about how to update statistics, it is more about how do I gather information about statistics. This information is important when troubleshooting a performance issue as well as a way to check to see if your statistics update strategy is effective in updating the statistics properly. Remember, if statistics are not updated properly or not created at all, this could lead to performance issues.
There are a few ways to gather statistics information, but before getting into those, let’s go over that information about statistics is important. This is not all the items, but they are the key ones.
Important Statistics Information
- What statistics exist
- Date they were last updated
- Is there a filter?
- Number of rows and the number of rows used for the sample
- How many modifications since the last statistics update
These are all important in one way or another. Here is why each of these is important to look at.
What Statistics Exist – This is important to know because sometimes what statistics we think exist may not actually exist. If the “Auto Create Statistics” database setting is turned off, then of course statistics would not be created other than manually or by creating an index.
Date They were last updates – This will help us understand if the statistics are being updated appropriately and as expected.
Is there a filter? – This will help us understand if the statistics are for the all the rows of the table or just a subset.
Number of Rows and the number of Rows used for the Sample – We need to review this to see if SQL Server is using an appropriate number of rows to update the statistics.
Number of Modifications since the last Statistics update – Understanding how frequently the column is modified will help us determine if the statistics update is happening appropriately. It is important to keep this in perspective. You can’t just look at this number, it is also important to look at the date last updated and the number of rows. If there are a high number of modifications but the statistics were last updated six months ago, there may not be an issue. Although I might want to look to see why the statistics haven’t been updated for 6 months.
How do I get this information
There are a couple of different ways to get this information.
SQL Server Management Studio
You can simply right click on the statistics object you want to review and click Properties. This will open up the properties window.
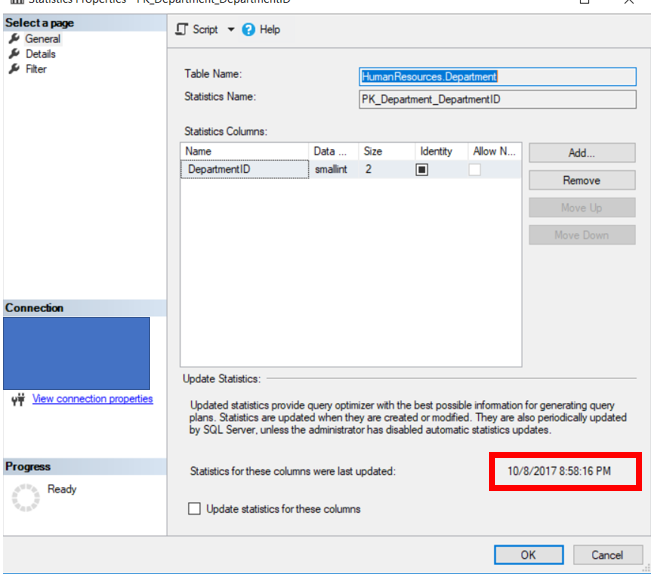
 On the first screen you will see this. You will be able to identify the date of the last update. It is highlighted below.
On the first screen you will see this. You will be able to identify the date of the last update. It is highlighted below.
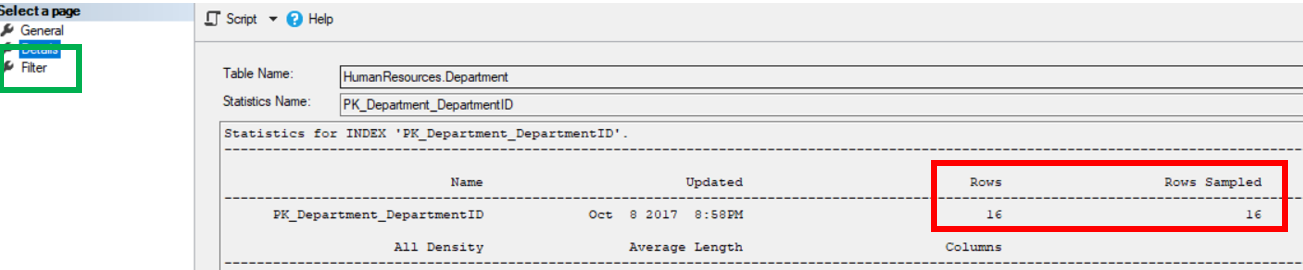
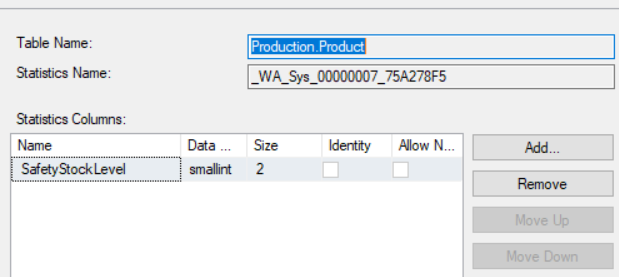
 The number of rows and rows used in the sample can be found in the “Details” tab, while the filter information can be found by clicking the “Filter” tab on the left.
The number of rows and rows used in the sample can be found in the “Details” tab, while the filter information can be found by clicking the “Filter” tab on the left.
What cannot be found by using the Properties window is the number of modifications since the last statistics update. This is kind of limiting.
There are two ways to get all the information above. One is to use DBCC SHOW_STATISTICS the other is to query the SYS.STATS table.
DBCC SHOW_STATISTICS
This statement will return all the above information in three data sets, the header, the density vector and the histogram. The syntax is below. We are not going to get into all the syntax, just the basics. If you want more information you can go here.
This is the basic syntax. The statement expects and table or view name and a statistics object name. The output is below.
DBCC SHOW_STATISTICS(‘person.person’, [IX_Person_LastName_FirstName_MiddleName])
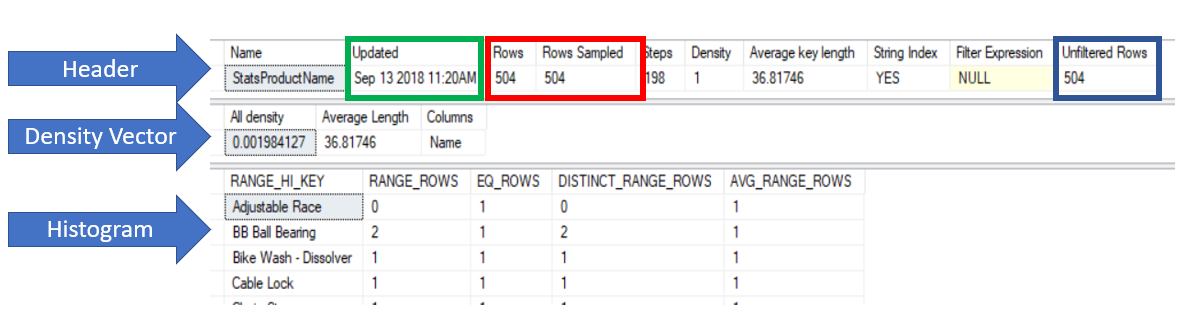
The three sessions, Header, Density Vector and Histogram are identified by the arrows. While the green box labels that date last updated, red is the number of rows and rows used as a sample. The final box is the blue box on the left, this identifies if there is a filer or not. Notice that to the left of that there is a column named “Filter Expression”. This will identify the expression used for the filter if one exists.
You can only return one of the sections by run one of the code snippets below.
DBCC SHOW_STATISTICS(‘production.product’,ReorderPoint)WITH STAT_HEADER
DBCC SHOW_STATISTICS(‘production.product’,ReorderPoint)WITH DENSITY_VECTOR
DBCC SHOW_STATISTICS(‘person.person’,[IX_Person_LastName_FirstName_MiddleName]) WITH HISTOGRAM
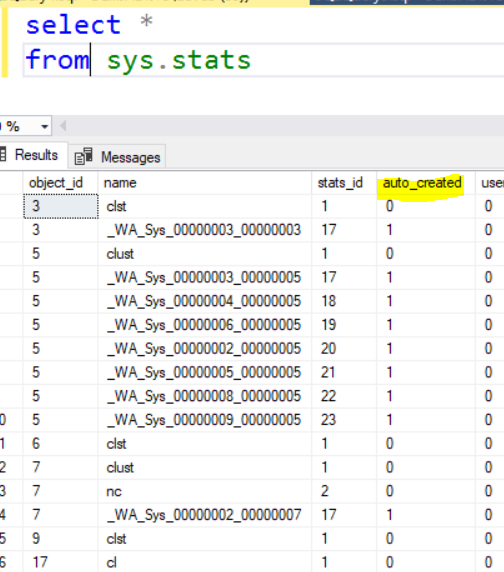
SYS.Stats
This is from Microsoft: “Contains a row for each statistics object that exists for the tables, indexes, and indexed views in the database“. In reality this really needs to be used with a few other statistics related objects. These related objects are sys.stats_columns and sys.dm_db_stats_properties. Below is the code that can be used to gather all the information and then some. This code can be found here.
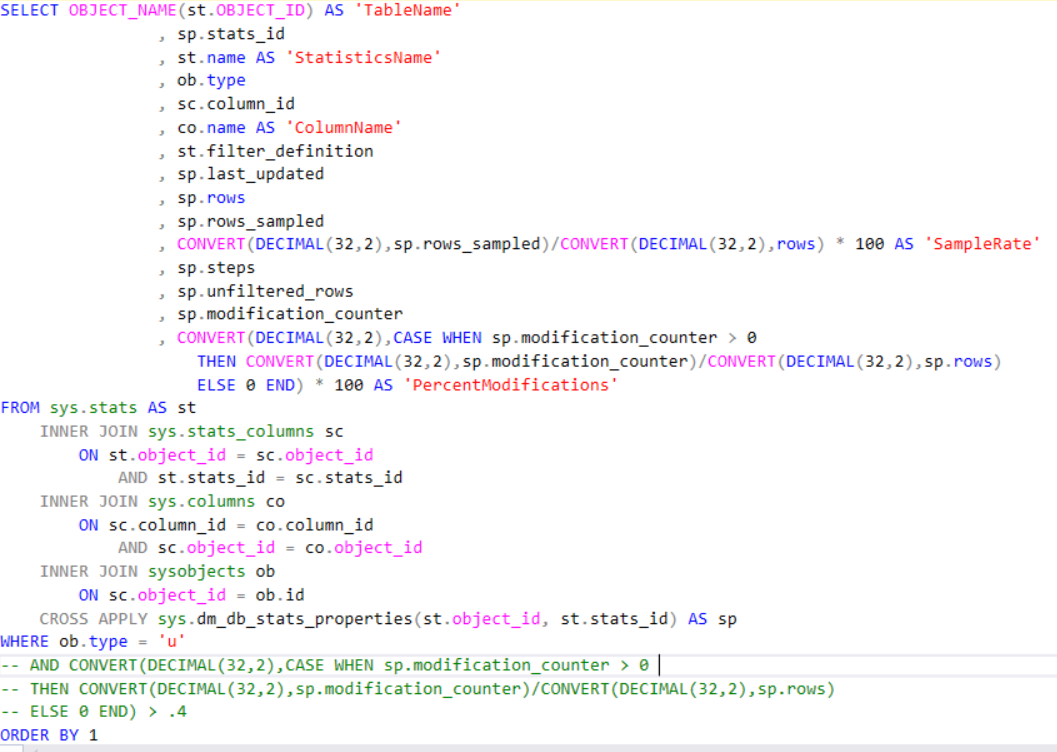
I just took the code that was provided by Microsoft and added the sysobjects table to allow for the data set to include the column name.
Notice that the dm_db_stats_properties obect is a function that has two parameters, objectID and StatsID.
Below are the results of the above statement. Notice that it includes all the items mentioned at the beginning of this post.

All the above methods return much of the information to review statistics. What I like about the last option, I can see all the statistics in one data set.
Here are a couple of good links to learn more about SQL Server Statistics.
Thanks for visiting and I hope you learned something!
 Once this is turned on, you can now run your query. When you do, a new tab will appear in the results pain, which will be labeled “Live Query Statistics”.
Once this is turned on, you can now run your query. When you do, a new tab will appear in the results pain, which will be labeled “Live Query Statistics”.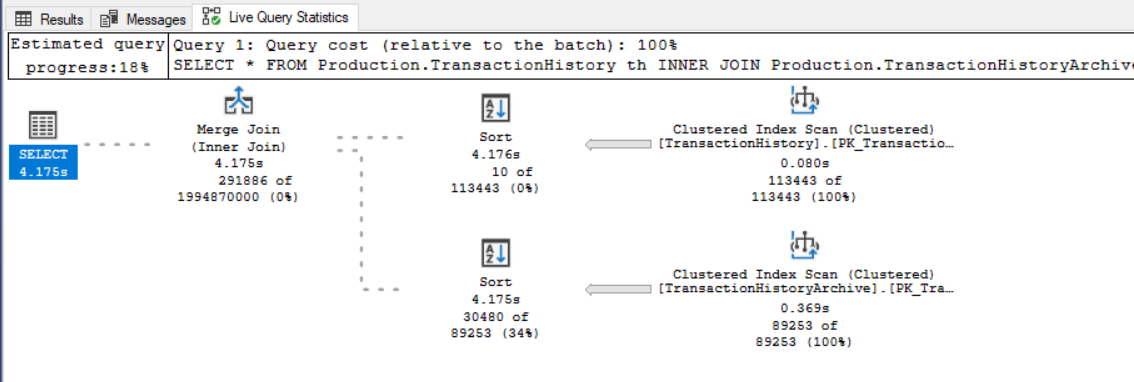
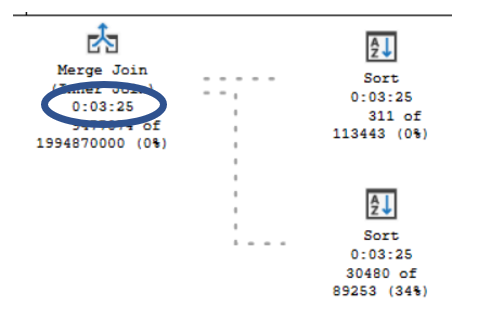
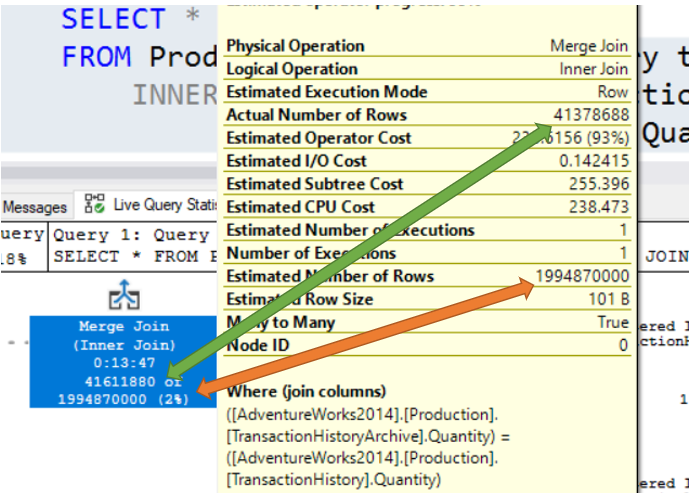
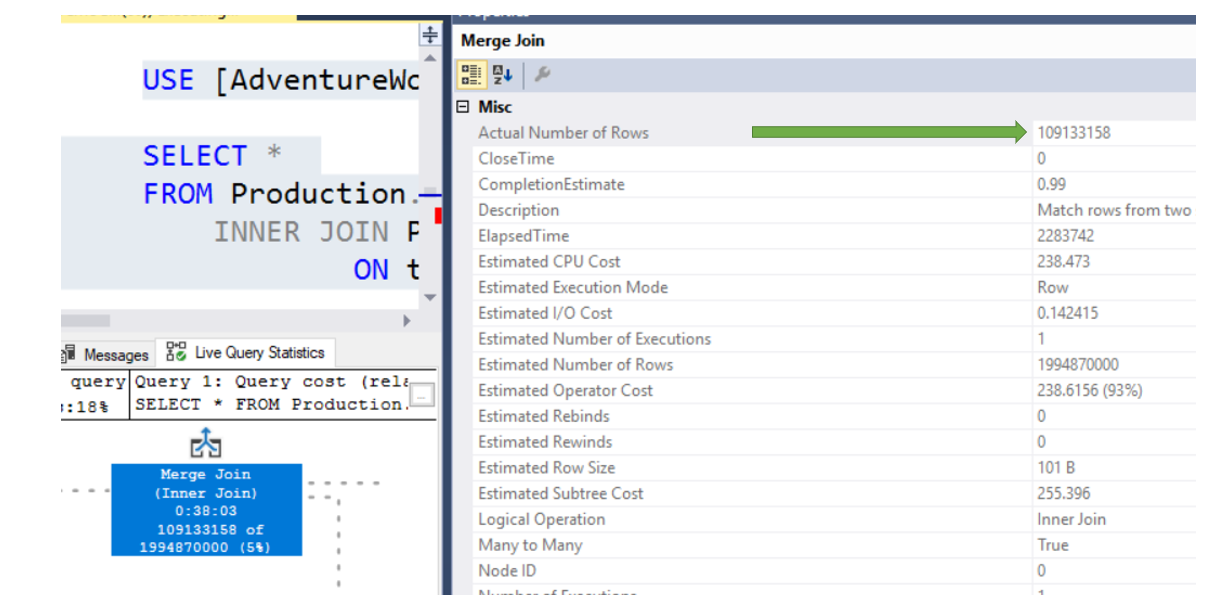
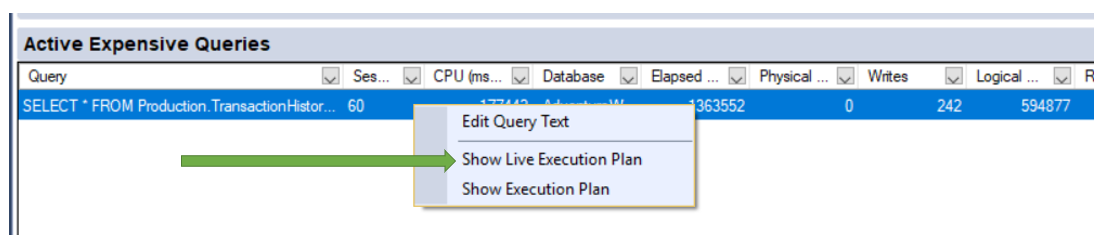
 Brent Ozar has a few really good posts that go more in depth about Live Query Execution Plans. I figured why reinvent the wheel. Here are the links to his posts.
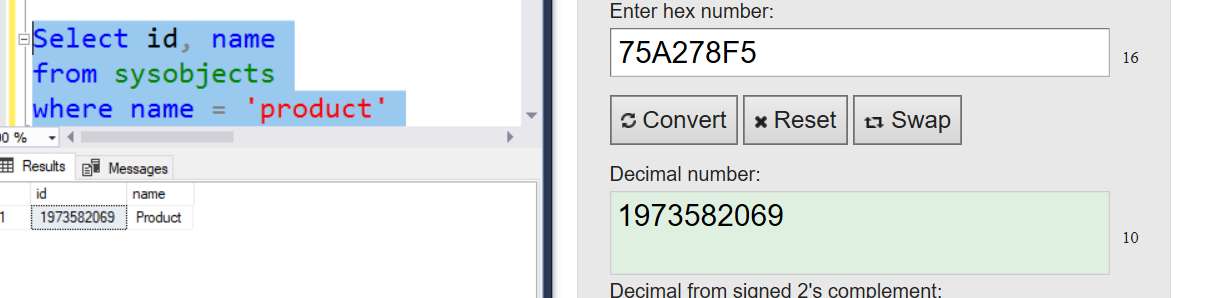
Brent Ozar has a few really good posts that go more in depth about Live Query Execution Plans. I figured why reinvent the wheel. Here are the links to his posts.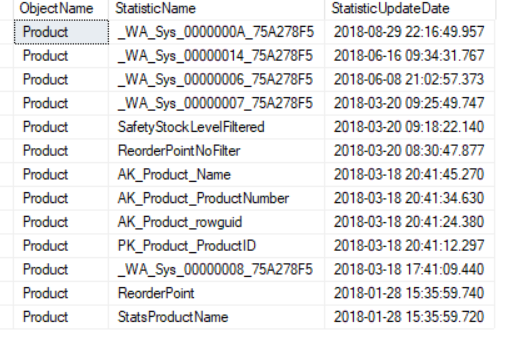 You can run the statement below that will list all the columns that have statistics. This statement can be found at here on
You can run the statement below that will list all the columns that have statistics. This statement can be found at here on 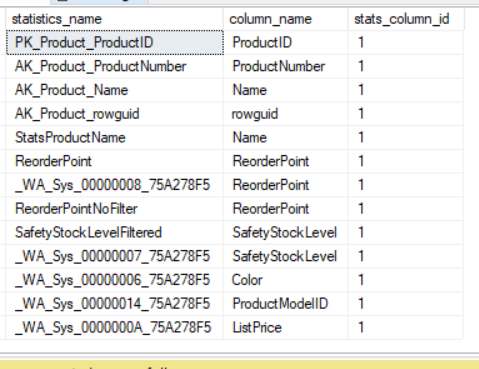
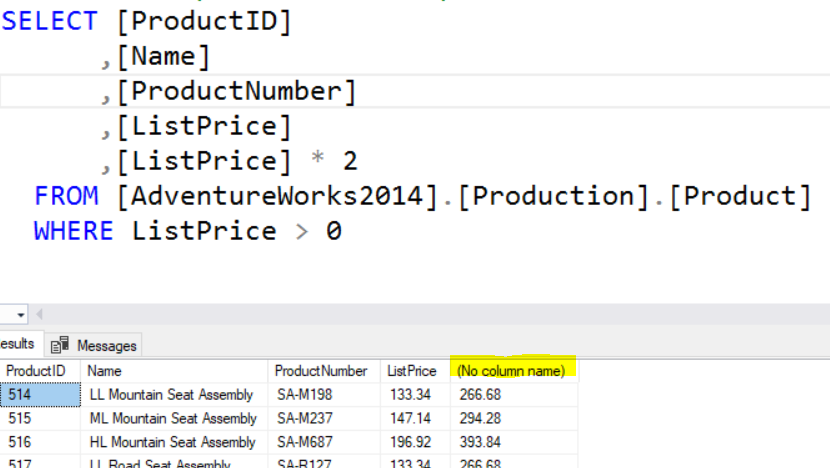
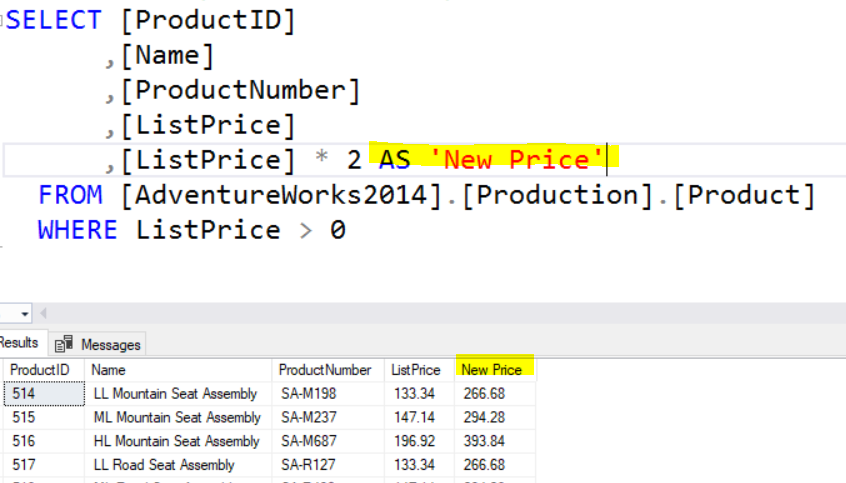
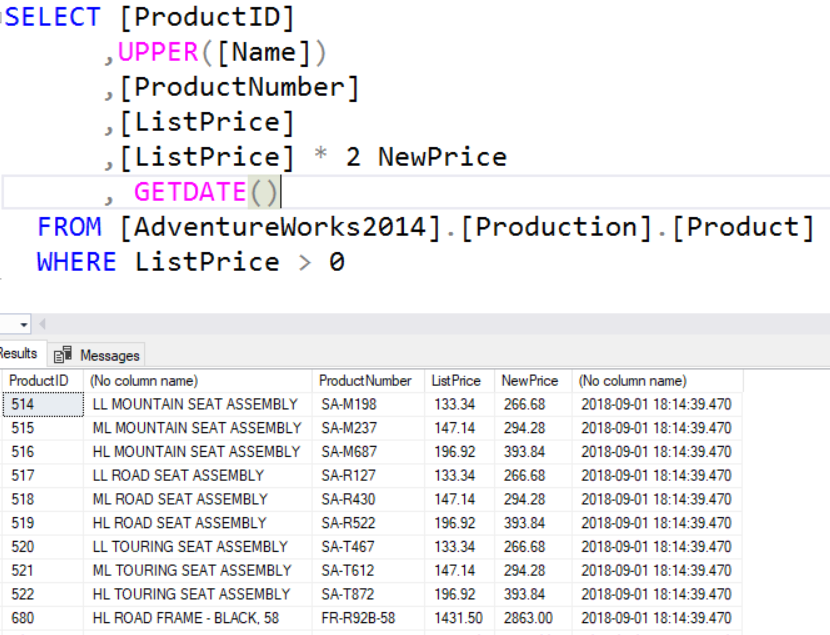
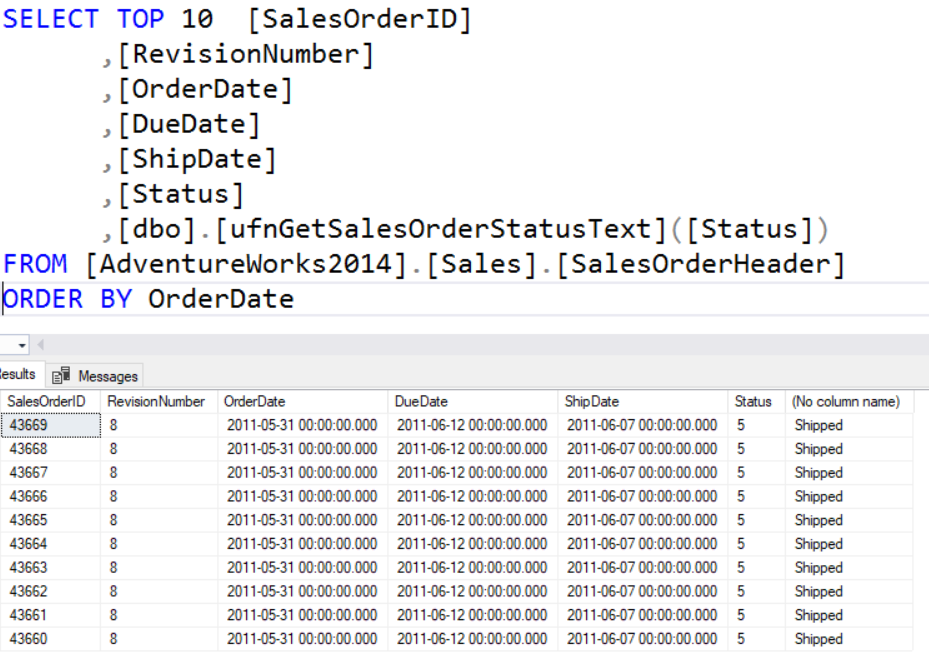
 In addition to actual column names you can also use calculated columns in the SELECT clause. However, when this is done the column name in the result set will be (No Column Name) unless a column alias is used.
In addition to actual column names you can also use calculated columns in the SELECT clause. However, when this is done the column name in the result set will be (No Column Name) unless a column alias is used.