Microsoft defines the PIVOT as:
“Rotates a table-valued expression by turning the unique values from one column in the expression into multiple columns in the output, and performs aggregations where they are required on any remaining column values that are wanted in the final output” – link here
If you have used Excel, you will find the results when using the PIVOT are very similar to a Pivot Table. Below is a screenshot of a Pivot table from a video from Microsoft, link here. Notice the values across the top and on the left side. The numbers in the middle are aggregations of the data.
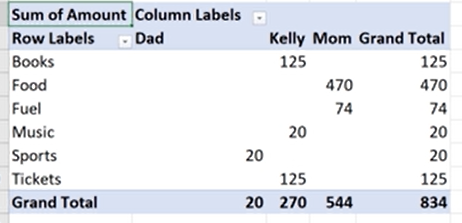
If you look at the example below of a result set using the TSQL PIVOT , you will notice the same structure. Values across the top and on the left side with aggregations in the middle.
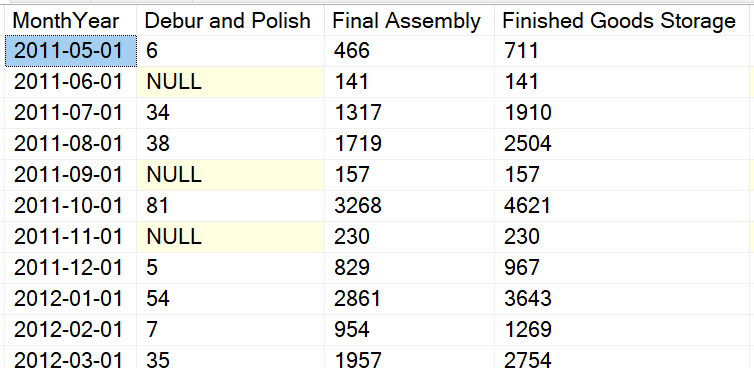
Now that we have talked about what the PIVOT command does, lets go over some basics.
- The PIVOT was first introduced into SQL Server with the release of SQL Server 2005
- The PIVOT keyword is placed after the FROM clause
- The resulting pivot table requires a table alias
- “When aggregate functions are used with
PIVOT, the presence of any null values in the value column are not considered when computing an aggregation.” – per Microsoft documentation
Elements of the PIVOT statement
Let’s go over the various parts of the PIVOT. Using the image below, I will dissect each component of the PIVOT command.
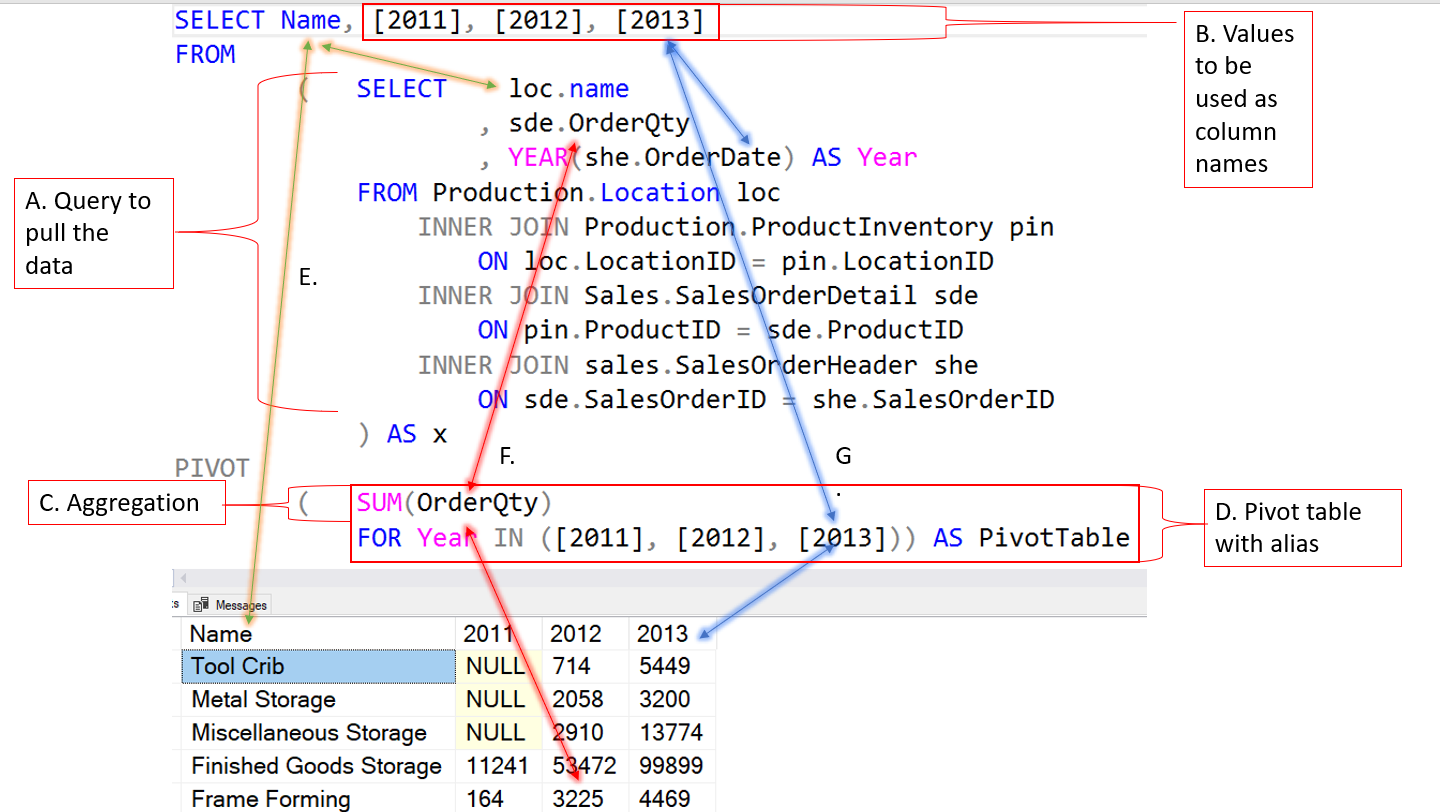
Part A
This is simply the TSQL statement that will pull the data you would like to use in the PIVOT. My suggestion is to get this query to return what you are looking to pivot first, then add the necessary code for the PIVOT around it.
Part B
These are hard coded values that will determine the names of the columns in the final result set. We will cover how to dynamically get the column names later in this post.
Part C
This is the column in the PIVOT table that will be aggregated.
Part D
This is the actual PIVOT table. Notice that the column does not appear to the pivot table at the bottom. Only the year and the aggregate column appear. As stated earlier, this requires an alias. If you do not use an alias you will receive this error.
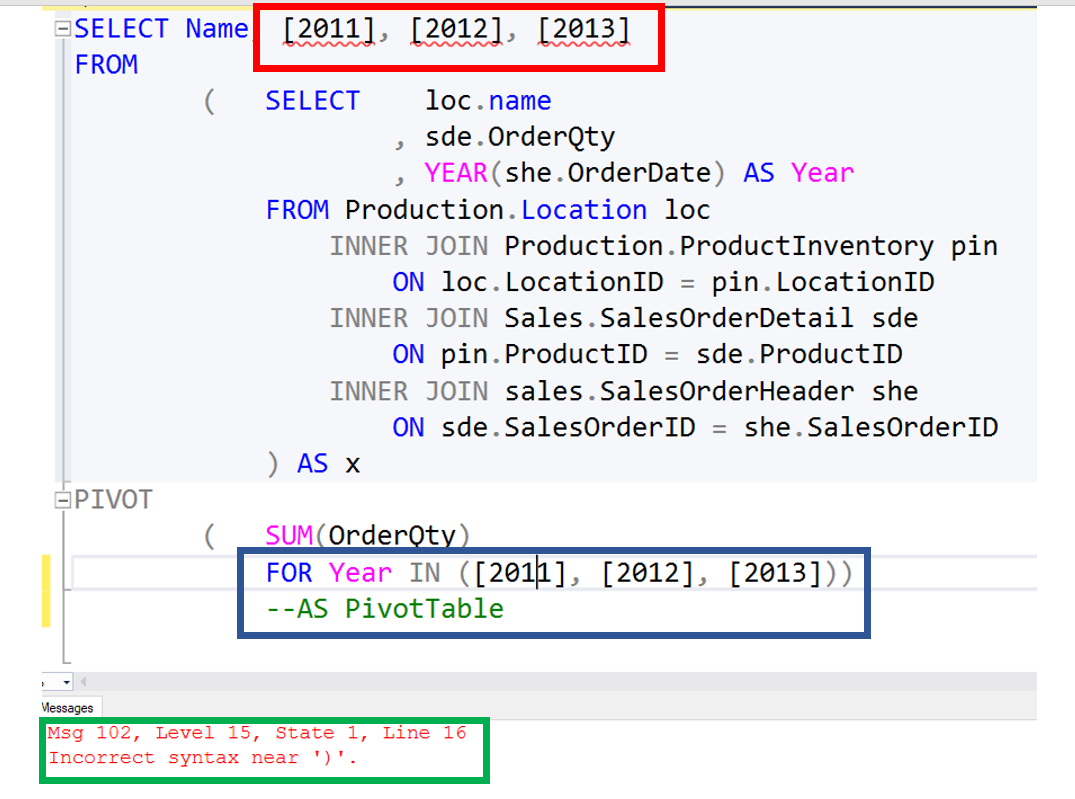
Msg 102, Level 15, State 1, Line 16
Incorrect syntax near ‘)’.
By looking at the image below, you can see the alias has been commented out. The causes the above error, as well the hard coded column to be marked with an invalid column name error.
Part E
In this case, it is the first column. It start with the Name column in the inner query and works its way to the outer query and eventually to the PIVOT table results. Notice that the column alias flows through the entire process. If you change the column alias in the inner query, you will also have to change it on the outer query as well. If you use an alias for the Name column in the inner query and you do not change the column name in the outer query you will see this error.
Msg 207, Level 16, State 1, Line 1
Invalid column name ‘Name’.
Part F
This is the aggregate column. The column in the inner query does not have a aggregate function on it, but it can if your needs dictate that it does.
Part G
These are both the column names and the values that will be used to complete the grouping for the aggregation. If you change one if them you will get an invalid column name error.
Here is the completed code. I used the AdventureWorks2014 database.
SELECT Name, [2011], [2012], [2013]
FROM
( SELECT loc.name
, sde.OrderQty
, YEAR(she.OrderDate) AS Year
FROM Production.Location loc
INNER JOIN Production.ProductInventory pin
ON loc.LocationID = pin.LocationID
INNER JOIN Sales.SalesOrderDetail sde
ON pin.ProductID = sde.ProductID
INNER JOIN sales.SalesOrderHeader she
ON sde.SalesOrderID = she.SalesOrderID
) AS x
PIVOT
( SUM(OrderQty)
FOR Year IN ([2011], [2012], [2013]))
AS PivotTable
What do I do if I don’t want to hard code the values for the column names?
This a question I get a lot in my classes. The answer is dynamic SQL. Yes I know about all the potential issue with dynamic SQL, so you need to exercise caution when doing this.
The first thing we need is a couple of variables.
DECLARE @cols AS NVARCHAR(MAX)
DECLARE @query AS NVARCHAR(MAX);
The first variable is to hold what will be your column names, while the second variable will be used to execute the SQL.
Next we need to go get the values we want to use as our column names. In order to do this we will use the keyword STUFF. What is STUFF, it simply is used to insert a string in a string….in other words, stuff a string in a string. Go here to get more detailed information about the STUFF keyword.
The STUFF keyword has four parameters.
- Character expression – this is the string we want replaced
- Starting point
- Length
- The string we are going to insert
We will also need to the QUOTENAME function, click here for more information. This function simply adds delimiters. If we look at the code below and PRINT the variable we will see this: [2011],[2012],[2013],[2014]
Below is the code we can use to get the column names. If you want to use this, all you have to do is replace everything from the CONVERT to the ASC with your query. Remember, it can only return one column.
SET @cols = STUFF((SELECT DISTINCT ‘,’ + QUOTENAME(
CONVERT(VARCHAR(4),YEAR(she.OrderDate))) AS Year
FROM Production.Location loc
INNER JOIN Production.ProductInventory pin
ON loc.LocationID = pin.LocationID
INNER JOIN Sales.SalesOrderDetail sde
ON pin.ProductID = sde.ProductID
INNER JOIN sales.SalesOrderHeader she
ON sde.SalesOrderID = she.SalesOrderID
ORDER BY YEAR ASC
FOR XML PATH(”), TYPE
).VALUE(‘.’, ‘NVARCHAR(MAX)’)
,1,1,”)
The next thing we need to do is set the variable for execution.
SET @query = ‘SELECT name AS LocationName, ‘ + @cols + ‘ from
(
SELECT loc.name
FROM Production.Location loc
INNER JOIN Production.ProductInventory pin
ON loc.LocationID = pin.LocationID
INNER JOIN Sales.SalesOrderDetail sde
ON pin.ProductID = sde.ProductID
INNER JOIN sales.SalesOrderHeader she
ON sde.SalesOrderID = she.SalesOrderID
) x
pivot
(
SUM(OrderQty)
FOR Year IN (‘ + @cols + ‘)
) p ‘
Finally the last step, execute the query.
EXECUTE(@query)
You will find the entire code here: PivotDemo.
While researching this post I found a very nice post about another method to use to do this using Json. It can be found on Red-Gate’s web site, this link is below.
Phil Factor from Red-Gate shows how to use Json to pivot: click here
Thank you for visiting my blog, hope you enjoyed and learned something!