The Select statement is one of 4 Data Manipulation Language(DML), the others being INSERT, UPDATE and DELETE. As expected the SELECT statement is used to extract data from a relational database such as SQL Server. This statement works in most database systems. Although, there may be some differences in the different products. These differences are not the focus of this post, we will concentrate on the use of the SELECT statement in Microsoft SQL Server. Over the years the SELECT statement has not changed much as versions of SQL Server are released, making this one of the statements that will work in older versions as well as the new ones. This is part 2 of the series.
The SELECT clause is just one of a few clauses in the SELECT statement. The others are FROM, WHERE, GROUP BY, HAVING and ORDER BY. In part 1 I discussed the order these clauses are processed. As a reminder, the SELECT clause is either last or second to the last in the processing order. If there is an ORDER BY, the SELECT is processed just before the ORDER BY. If there is not an ORDER BY, then the SELECT is the last clause processed. The focus of this post is just the SELECT clause.
The SELECT clause can easily be described as the place where you identify what columns you want to be included in the result set. These columns can be columns from the table or view, an expression or the results of a scalar function. In addition to what columns you want included in your result set, the SELECT clause is also where the order in which those columns appear in the result set is determined.
When deciding what columns from the tables to be included in the SELECT clause, it is important to only return the columns that are needed. Avoid using “SELECT * FROM….”. Sometimes it is simply easier to use SELECT *, however there are consequences to using it, mostly the potential impact on the performance of the query. When listing the columns they need to separated by a comma. Below you will find an example. The “[” and “]” are used when the column name contains a space. You will also see them if you right click on a table and click “Select Top x rows” in SSMS.
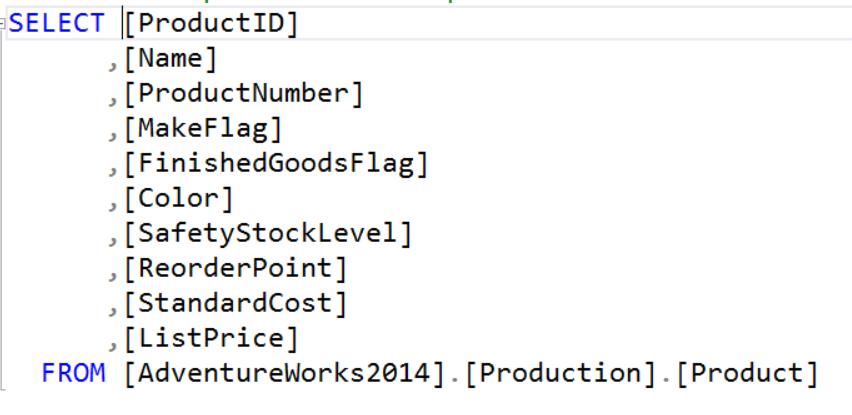 In addition to actual column names you can also use calculated columns in the SELECT clause. However, when this is done the column name in the result set will be (No Column Name) unless a column alias is used.
In addition to actual column names you can also use calculated columns in the SELECT clause. However, when this is done the column name in the result set will be (No Column Name) unless a column alias is used.
Result Set without a column alias:
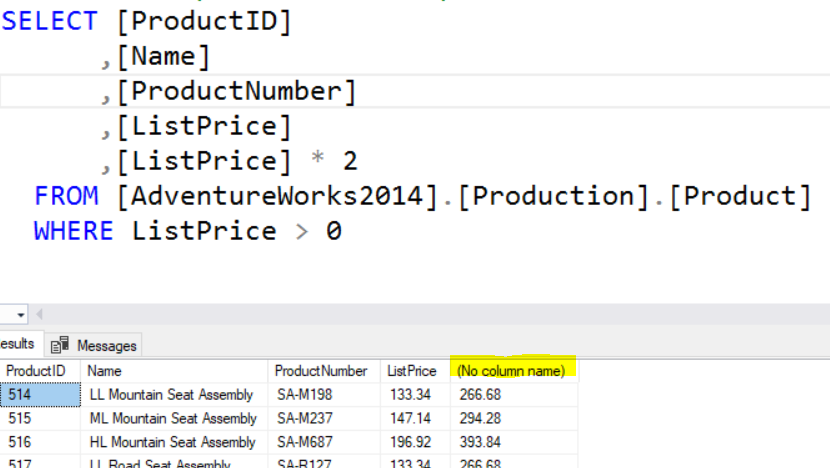
The example below show how a column alias can be used. The “AS” keyword isn’t required. The single quotes surrounding “New Price” are also not required as long as the alias name does not include spaces. Personally I also like to include them regardless if there is a space or not. There really aren’t a lot of requirements for column aliases although I would try to avoid using keyword and actually column names.
Scalar Functions
Scalar functions can also be used in the SELECT clause. These functions can be system supplies functions or user defined functions. Really the only requirement is that it must be a scalar function, not a table valued function. Just a reminder, a Scalar function is a function that returns a single value. So when one is included in a SELECT statement, it will run the same number of times as there are rows returned.
Here are some examples of a few native SQL Server built-in functions. More information can be found here: More Info on Functions
| LEFT | RIGHT | LEN |
| UPPER | LOWER | REVERSE |
| TRIM | GETDATE | DATEDIFF |
| UPPER | LOWER | TRY_CONVERT |
When using these functions, many times the arguments will be populated with column names. Although that is in no way a requirement.
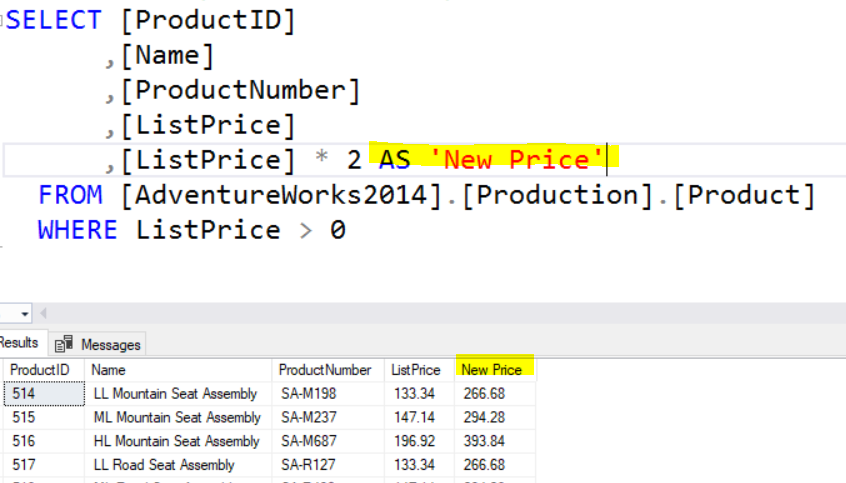
Below you will find an example of using two Built-In functions. One, UPPER, requires an argument to be used while the second, GETDATE(), does not. However, both would need a column alias. This would be the same if using User Defined Functions(UDF).
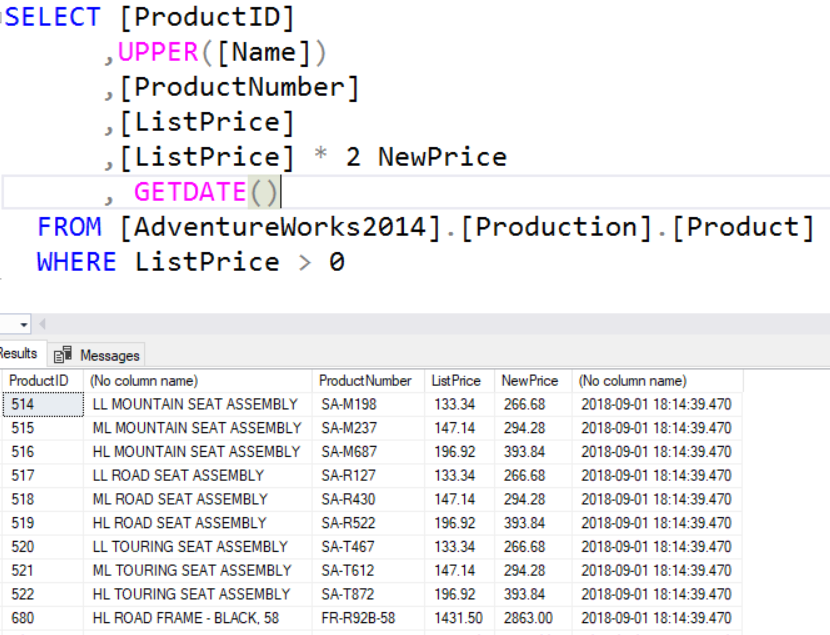
Example using a UDF. In this case it is the ufnGetSalesOrderStatusText UDF in the AdventureWorks database. It accepts TINYINT value as an input parameter and will return the text description of the status.
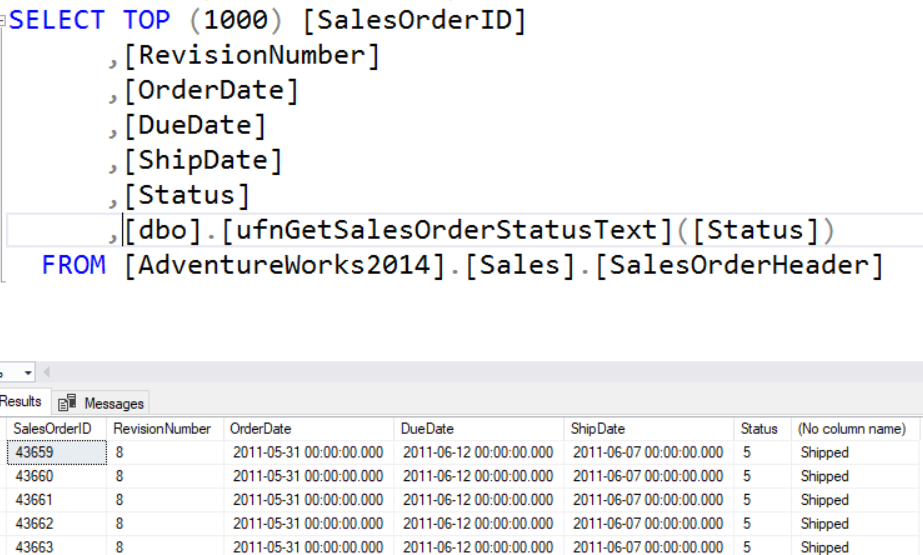
If you run the above query without the TOP clause, you will see that this query returns over 31,000 records. This means that the UDF will execute over 31,000 times. This is important to know in case there are performance issues.
TOP
We have discuss adding columns, column aliases as well as the use of scalar functions in the SELECT clause. Now lets talk about the TOP key word. This appears immediately after the SELECT key word. This is used to limit the number of rows to a specific number, TOP(10) or percent of rows, TOP 10 PERCENT. The TOP key word is usually used in conjunction with the ORDER BY clause. If no ORDER BY clause is included, then SQL Server will per Microsoft, “it returns the first N number of rows in an undefined order”.
In the example below, only 10 rows are return based on the oldest 10 records when sorted by the OrderData. Remember, the default sort order is ascending. Notice that there are not parenthesis around the number 10. Again, not required at this point, but will be in the future.
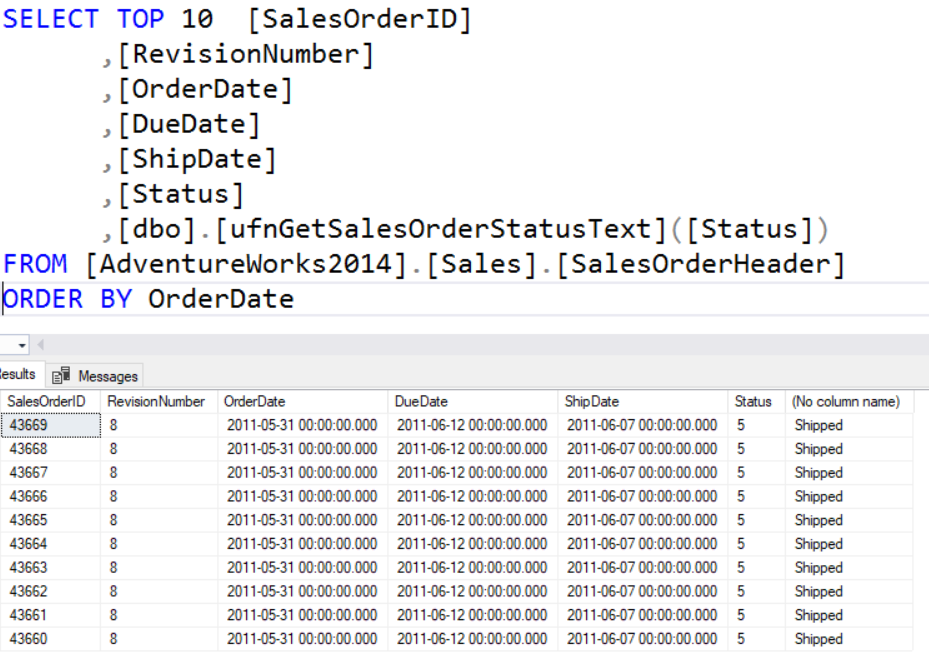
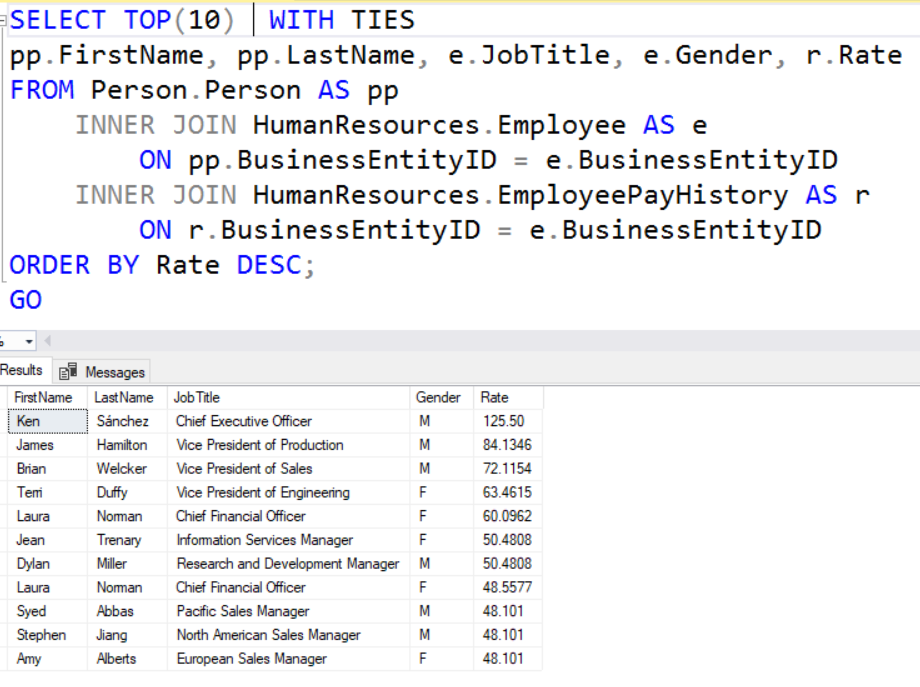
Notice above that the OrderDate is the same. That is because it only returned the top 10 records. Well what if there are more than 10? This is where WITH TIES comes in. If you look at the example below you will see that there are 11 rows. This is because the 11th row match the value of the 10th row. WITH TIES will return if there are additional matches with the value in the last row.
$ROWGUID and $IDENTITY
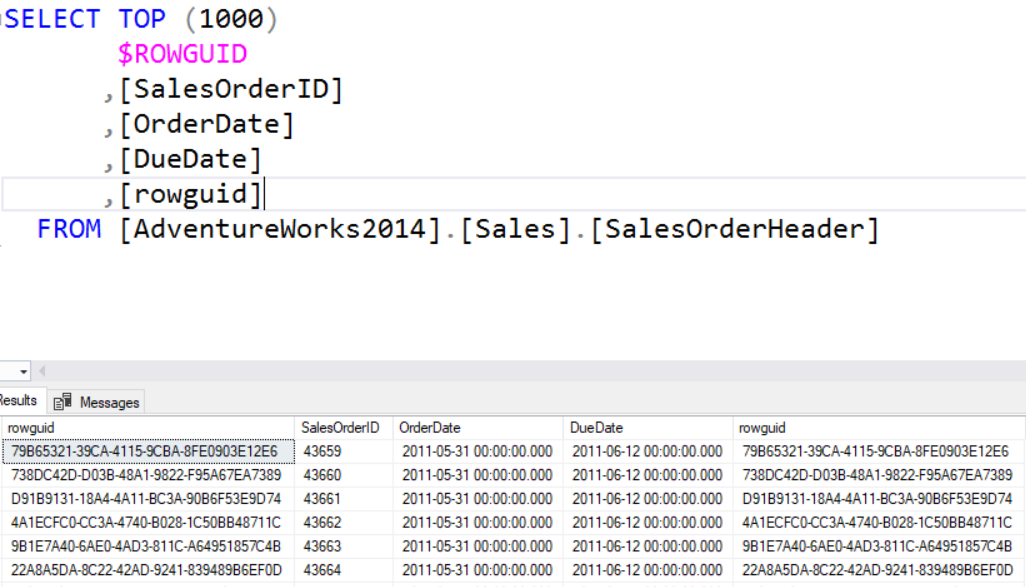
These two functions are used with tables that have an Identify column or a column using the ROWGUIDCOL property. With both $ROWGUID and $IDENTITY you actually don’t need to know the name of the columns. If you attempt to use either of these on a table that does not have the proper column types will result in an invalid column error.
Notice in the example below, the first column and the last column in the result set are the same. The $ROWGUID column, the first column, will also assume the column name of the source column as well. $Identify works in the same way.
DISTINCT
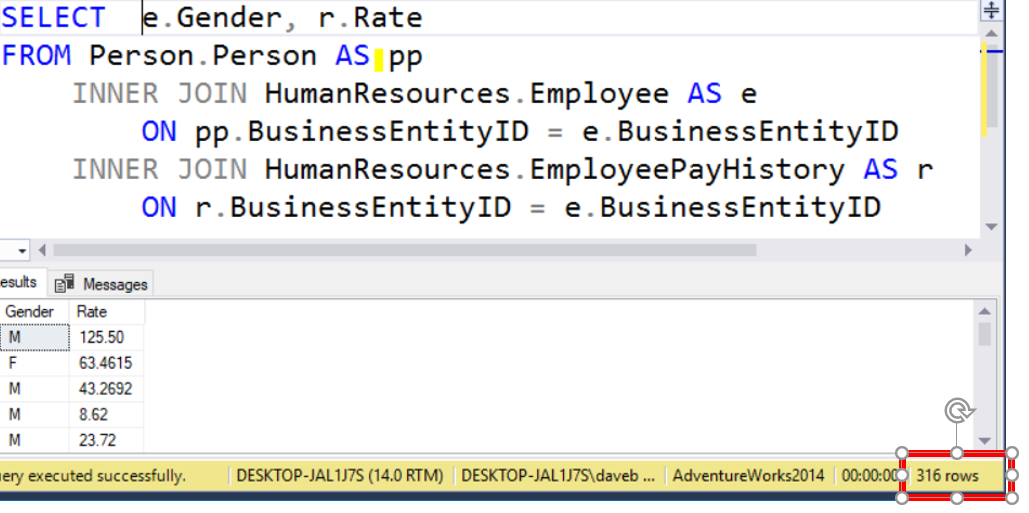
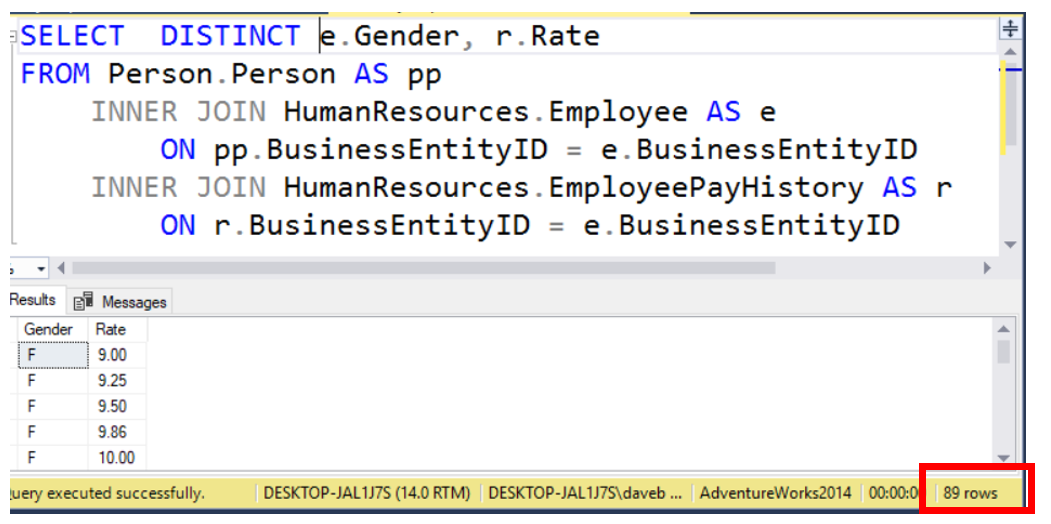
The last topic in the post is the use of the key word DISTINCT. DISTINCT is used to eliminate duplicates in the result set. Per Microsoft, NULLS are considered equal for the DISTINCT keyword.
If you look below you will see that the number of rows returned is 316. If you add the keyword DISTINCT the number of rows returned drops to 89. With this query, all duplicates based on Gender and Rate are removed.
During the post we have discussed many of the items that can be included in the SELECT clause. This includes column aliases, user defined functions, built-in functions, TOP and DISTINCTS keywords as well as a few other topics.
Hopefully you leaned something and thank you for visiting my blog. In the next post I will dissect the FROM clause.
Previous parts of the Series
Part 1 – Order of the Clauses in the SELECT statement