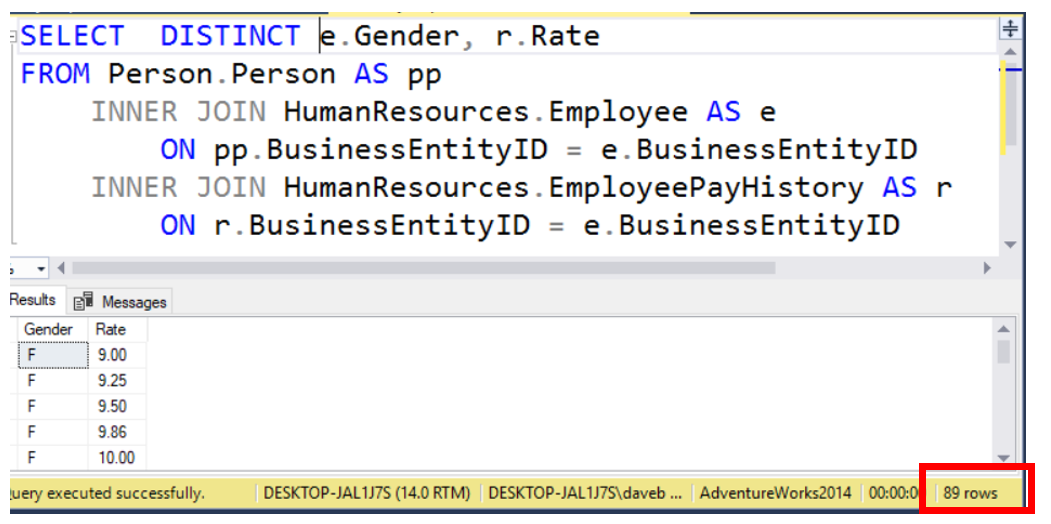
Welcome to part 3 of this series. The first part covered the order of execution of the commands, while the second session went in depth about the SELECT command. This post will cover the FROM clause. Most people would think that you will list tables in the FROM clause. Yes, that is correct, however you can do so much more.
What can be listed in the FROM
This first step is to list what can you use in the FROM clause. The list includes the below list.
- Table
- View
- Temporary Table
- Table Variable
- Derived table
- Table valued functions
We will cover each of these.
Table and View
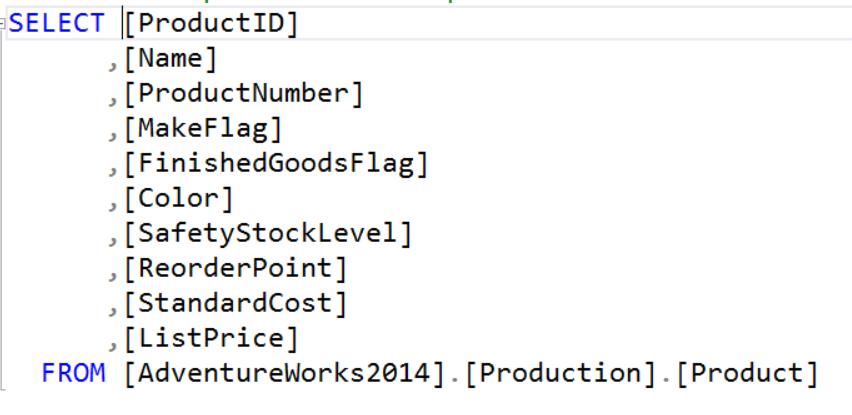
Tables and views are probably the most common objects used in the FROM, although I really don’t have any exact statistics on that. Below is an example is a simple query.
SELECT TOP (1000) [ProductID]
,[Name]
,[ProductNumber]
,[MakeFlag]
,[FinishedGoodsFlag]
,[Color]
,[SafetyStockLevel]
,[ReorderPoint]
,[StandardCost]
,[ListPrice]
FROM [AdventureWorks2014].[Production].[Product]
In the FROM clause you will see the table or view. Notice that not only is the table name listed, but the database and schema are also specified. Those two are not require, but I might not be a bad idea to start listing the schema as well as the table name.
By looking at this statement, we can only speculate that the object listed is a table. If you use a view instead, they will look that same. Really the only way to tell if the object is a table or view is to simply know what type of object it is. You can look in the objects explorer in SSMS and look for the object. Sometimes using the naming convention can also be used to make this determination.
Temporary Table
Temporary tables are created in the TempDB system database. A temporary table can be identified by the start of the table name. The name will start with either # or ##.
Phil Factor on Red-Gate’s web site gives a great description of when we should use temporary tables. Here is the link: RedGate
“They are used most often to provide workspace for the intermediate results when processing data within a batch or procedure. “
When a temporary table starts with # it is a “local” table. This means that the only process that can see and use the temporary table is the one that created it. While global temporary tables will start with ##, they are not as secure because they can be used by other processes.
Since local temporary tables are used only by the process that created it, it will automatically be dropped when the connect that created it ends. Global temporary tables could persist a bit longer because it will remain until all processe that are using it are terminated. This post isn’t an in depth discuss about temporary tables, you can to here to get more information: TempTables.
Prior to using a temporary table, it must be created. You can use the CREATE TABLE statement or use SELECT…INTO.
–Create the table
CREATE TABLE #test
(ProductName VARCHAR(50)
, Price MONEY)
–Populate the table
INSERT #test
SELECT Name
, ListPrice
FROM Production.Product
–Use the table
SELECT *
FROM #test
In the code above you will see three distinct sections. The first is to create the temporary table, populating the table is the second and the third and last step is the use the table.
If you attempt to query the table and it is out of scope you will get the following error.
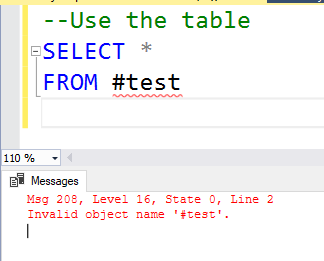
You receive this error because with a local temporary table, it is only available to the session that created it. That is not the case with a global temporary table, one that starts with ## rather than # for a local table.
However if you change from a local to a global temporary table, you will not receive the above error. You will actually get the results you are hoping for. If you look at the image below, you will see that the table was create with SPID 51 and used with SPID 60. Also note that even though it is a valid table, SSMS is still indicating that it is an invalid object in SPID 60. Of course that is not the case, it works just fine.
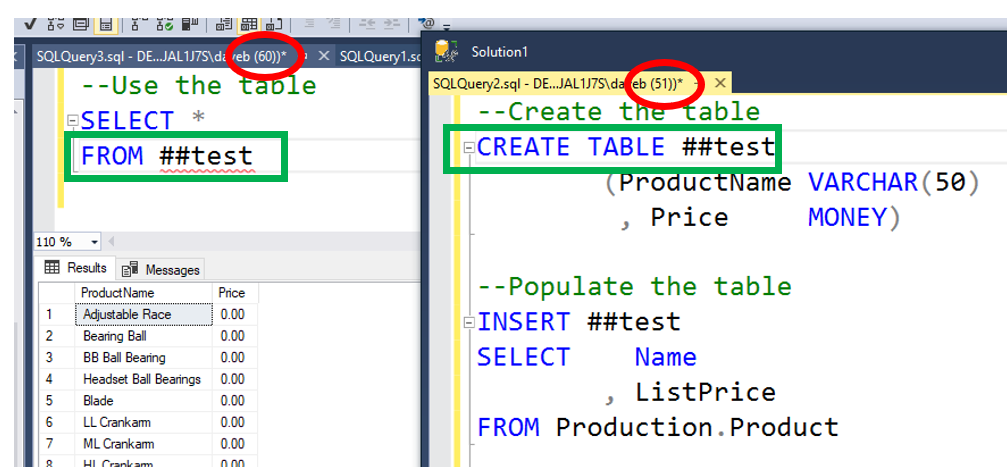
As you can see, temporary tables are used in pretty much the same way as user tables in a database. You just need to be aware of the scope of the table, is it local or global.
Table Variable
A table variable follows the same steps for creation and use. Instead of using the CREATE TABLE statement, when using a table variable, you use the DECLARE statement to declare the variable as a TABLE datatype.
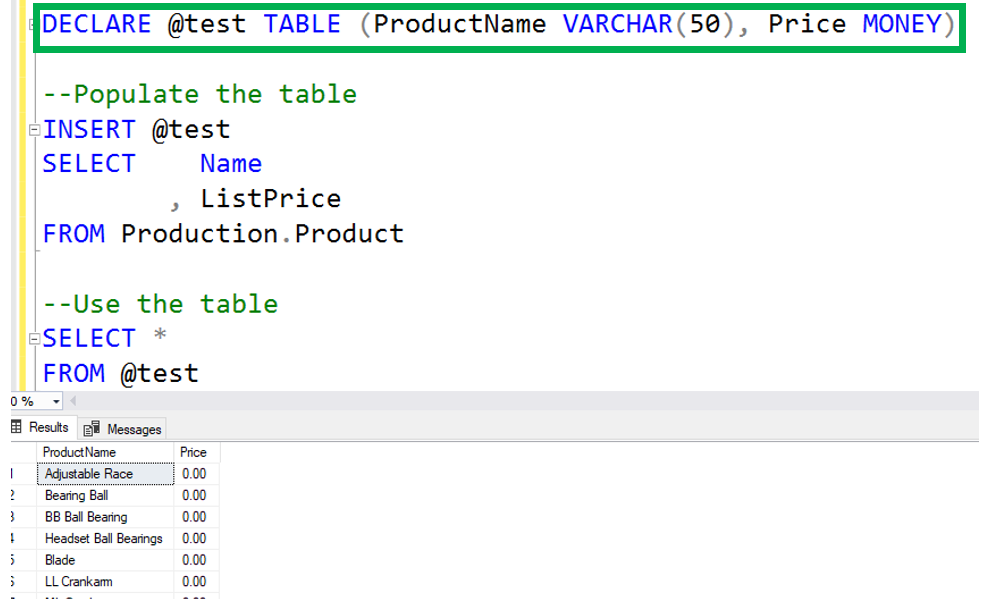
The scope of a table variable is the batch. If you create a temporary table you can use it for the duration of the session. While the duration of a table variable is the batch itself.
There are some differences on how SQL Server processes temporary tables and table variables. That is not the purpose of this post. You can go here to find more information regarding the differences.
Derived table
When I teach the Microsoft SQL Server certification course on TSQL, a derived table is in the same chapter as subqueries. A derived table is really not much more than a SELECT statement in the FROM clause instead of a table name. As you can see from the code below, the derived table is highlighted. The derived table has an alias of “v” and is enclosed in parenthesis.
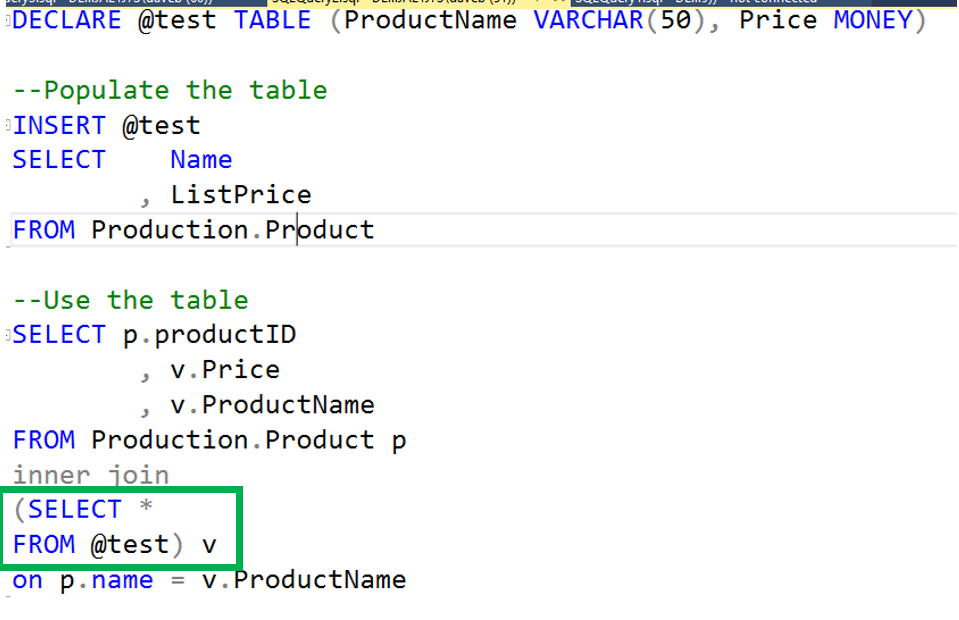
Table Valued Function
Like temporary tables and table variables, before using a table valued function(TVF) the function must be created.
The code below shows how to create the function. This function returns a table. This is from Microsoft’s web site. This will work on the AdventureWorks2014 database.
CREATE FUNCTION ProductsCostingMoreThan(@cost money)
RETURNS TABLE
AS
RETURN
SELECT ProductID, ListPrice
FROM Production.Product
WHERE ListPrice > @cost
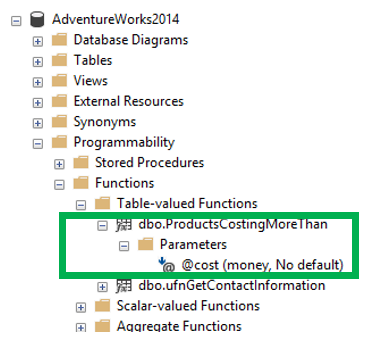
Once the function is created you can see in SSMS under Programmability.
One of the advantages of a TVF is that they can accept parameters. In the code above, the parameter is for the list price. In the code below you will that the TVF is used just a user table might be. Also notice the parameter being passed into the function.
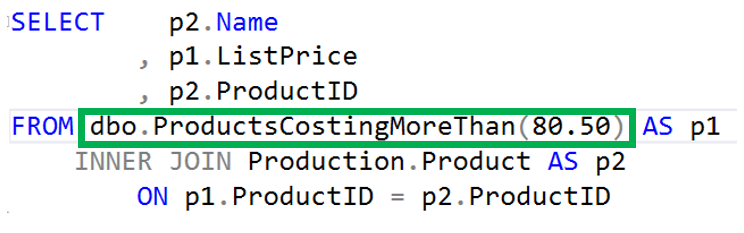
In this case, we are looking for any products that cost more than $80.50 and then joining it on the Product table.
Each of these objects has performance advantages and disadvantages. That is not the purpose of this post, however it is something that must be considered when determining the appropriate solution.
In the Part 4 on this topic, I will cover JOINS.
Thank for visiting my blog. I hope you learned something.
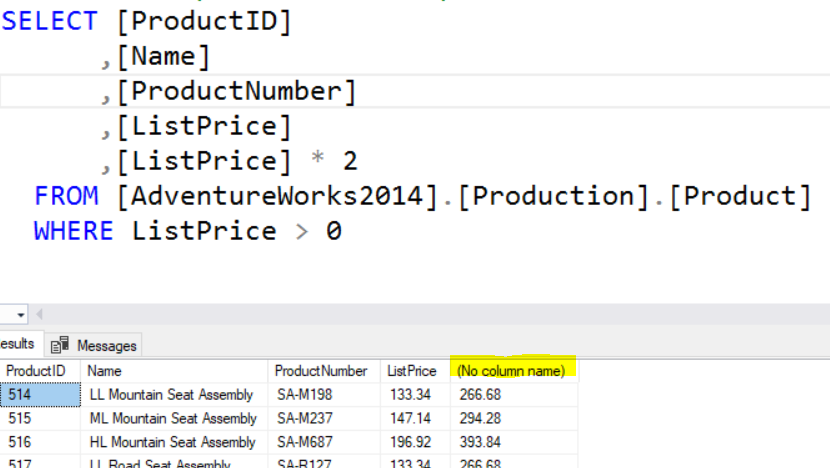
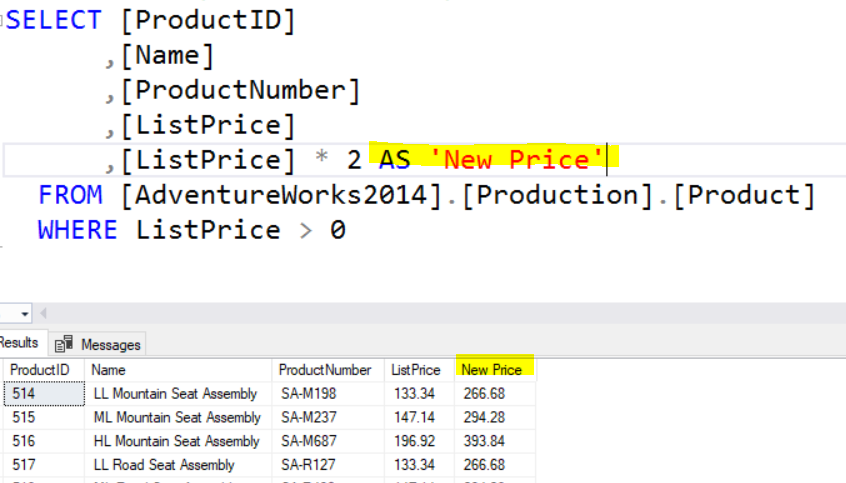
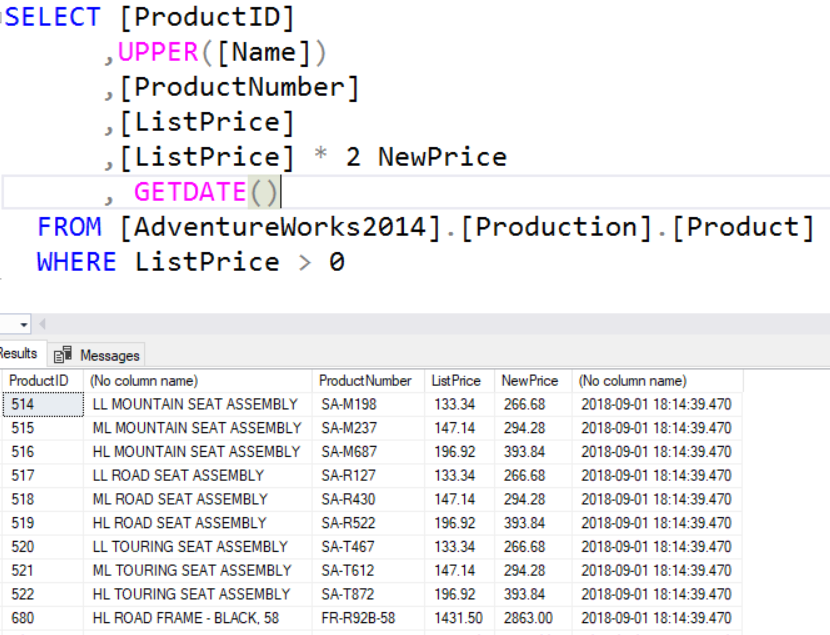
 In addition to actual column names you can also use calculated columns in the SELECT clause. However, when this is done the column name in the result set will be (No Column Name) unless a column alias is used.
In addition to actual column names you can also use calculated columns in the SELECT clause. However, when this is done the column name in the result set will be (No Column Name) unless a column alias is used.