After a short break from this series, I was thinking it was time to add another post to the Anatomy of the SELECT statement series. This post will focus on the GROUP BY and the HAVING clauses. These two statements can be used together, although when using the GROUP BY a HAVING is not required. So far in the series we have covered the SELECT, FROM, JOINS clauses as well as the order of processing. We have also covered the PIVOT, which follows the FROM clause.
The GROUP BY can be used to get an aggregation for a group. For example it can be used to get the number of times each product has been sold. As with most of my other posts, all examples in this post will use the AdventureWorks2014 sample database.
SELECT p.ProductID, p.name, COUNT(p.name) AS ‘NumberOfTimesSold’
FROM Production.product p
INNER JOIN Sales.SalesOrderDetail s
ON p.ProductID = s.ProductID
GROUP BY p.ProductID, p.name
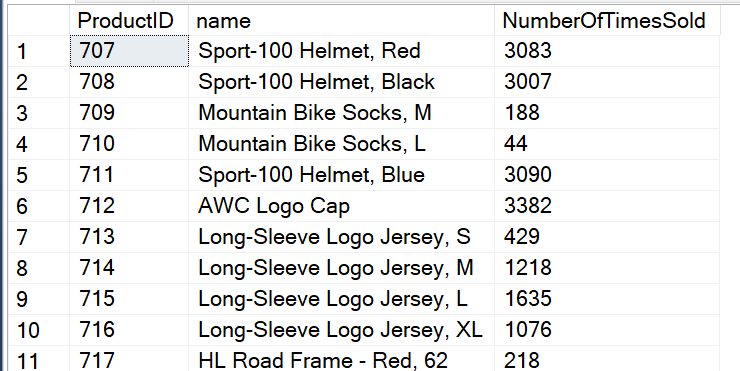
In the above statement, notice the use of an aggregate function. This is really what the GROUP BY is about. The GROUP BY and the use of the COUNT() aggregate function work together to get the results I am seeking, the number of times each product has been sold.
Requirements of the GROUP BY
As with all other statements and clauses in TSQL, there are requirements that must be followed. Below are the basic requirements of the GROUP BY.
- Cannot use a column from an indexed view
- The column used in the aggregate function does not need to appear in the SELECT list
- Cannot group on the following data types
- XML
- TEXT
- NTEXT
- IMAGE
- Can group on XML if the column is using in a function that outputs an acceptable datatype
- All columns must either be in the GROUP BY or in an aggregate function
Using the GROUP BY
Now that we have covered a few of the requirements. let’s see how we can use the GROUP BY.
Using the same code as in the example above, let’s dig a little deeper.
SELECT p.ProductID
, p.name
, p.Color
, COUNT(s.ProductID) AS ‘NumberOfTimesSold’
FROM Production.product p
INNER JOIN Sales.SalesOrderDetail s
ON p.ProductID = s.ProductID
GROUP BY p.ProductID, p.name, p.color
As you can see, the GROUP BY will follow the FROM clause and any joins. After the GROUP BY you will simply list the columns you would like to have each group be made of. The order of the columns listed in the GROUP BY does not matter and will not change the results or the column order in the results set, that is determined by the SELECT list. You can list them in any order you like, although I prefer to list them in the same order as they appear in the SELECT list. Again, that is just a preference and not a requirement of TSQL.
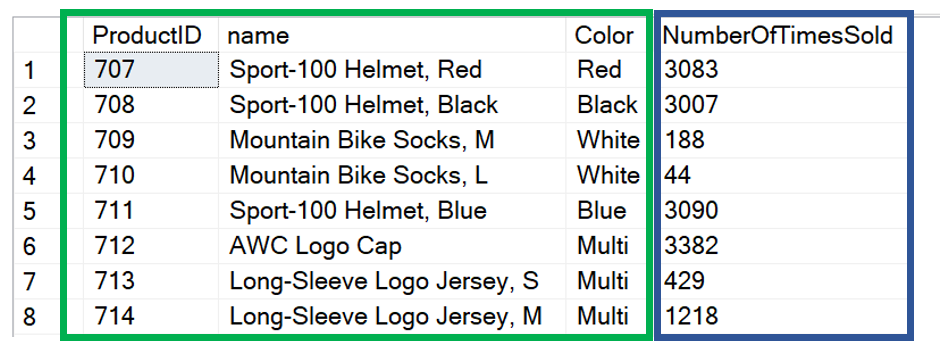
In the example, the groups will consist of the Productid, name and color columns. If you look at the image below, the columns in the green box make up the group, while the column in the blue box represents the aggregation, in this case it is a COUNT.
When using the GROUP BY, all columns in the SELECT must either be in the GROUP BY or using an aggregate function. If this requirement is not met, you well see this error:
Msg 8120, Level 16, State 1, Line 2
Column ‘Production.product.Name’ is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause.
To prevent this error, I like to do a simple test. Look at each column and check to see if it is in the GROUP BY or using an aggregate.
SELECT p.ProductID –Is in the Group by
, p.name –Is in the Group by
, p.Color –Is NOT in the Group by, will cause an error
, COUNT(s.ProductID) AS ‘NumberOfTimesSold’ –Is using an aggregate
FROM Production.product p
INNER JOIN Sales.SalesOrderDetail s
ON p.ProductID = s.ProductID
GROUP BY p.ProductID, p.name
Can Expressions be used in the GROUP BY?
Now let’s change what we are looking for. Let’s now look for how many times each product was sold by year and month. In order to do this, I can use an expression on the GROUP BY clause.
SELECT p.name
, MONTH(h.orderdate) AS ‘MONTH’
, YEAR(h.orderdate) AS ‘YEAR’
, COUNT(s.ProductID) AS ‘NumberOfTimesSold’
FROM Production.product p
INNER JOIN Sales.SalesOrderDetail s
ON p.ProductID = s.ProductID
INNER JOIN Sales.SalesOrderHeader h
ON s.SalesOrderID = h.SalesOrderID
GROUP BY p.name, MONTH(h.orderdate), YEAR(h.orderdate)
ORDER BY Year DESC, Month DESC
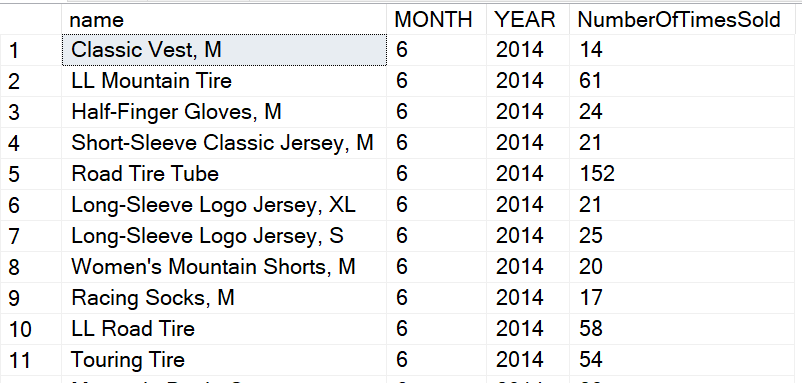
Notice in the GROUP BY the MONTH and YEAR functions are being used. As you can see in the results below, the “Classic Vest, M” product was sold 14 times during the month of June 2014.
Final thoughts on GROUP BY
Using the GROUP BY really isn’t very complicated, you just need to do three things:
- Determine what columns you want to make up the groups
- Determine which aggregate function you would like to use
- Before running the statement, check all the columns in the SELECT list to make sure each column is either in the GROUP BY or using an aggregate function
Using the HAVING
Now that I have my groups and my aggregate totals, what if I want to apply a filter to the results, similar to the WHERE clause? That is where the HAVING comes in. You can think if this as a where clause for groups. The HAVING clause appears after the GROUP BY and includes both the HAVING keyword and an expression. In the case below, the expression is COUNT(s.ProductID) > 10.
SELECT p.name
, COUNT(s.ProductID) AS ‘NumberOfTimesSold’
FROM Production.product p
INNER JOIN Sales.SalesOrderDetail s
ON p.ProductID = s.ProductID
INNER JOIN Sales.SalesOrderHeader h
ON s.SalesOrderID = h.SalesOrderID
GROUP BY p.name
HAVING COUNT(s.ProductID) > 10
Using HAVING also requires the use of an aggregate function. This aggregate really should be the same as what is in the SELECT list. If you do not include an aggregate and use something like this, HAVING s.rowguid > 10, you will get the error below.
Msg 8121, Level 16, State 1, Line 11
Column ‘Sales.SalesOrderDetail.ProductID’ is invalid in the HAVING clause because it is not contained in either an aggregate function or the GROUP BY clause.
Conclusion
Using the GROUP BY and HAVING clauses are very commonly used and having a good understanding of them is essential for anyone who writes TSQL code. Below you will find two links to documentation from Microsoft
Thanks for visiting my blog and I hope you learned something!

