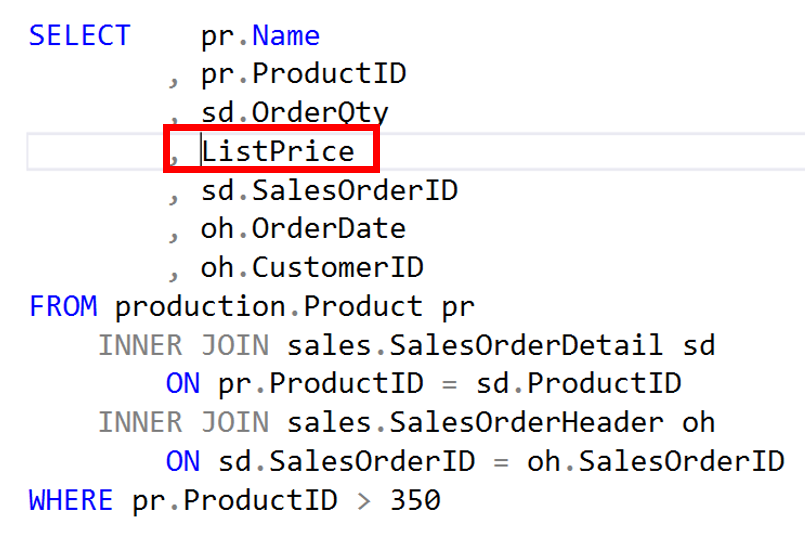
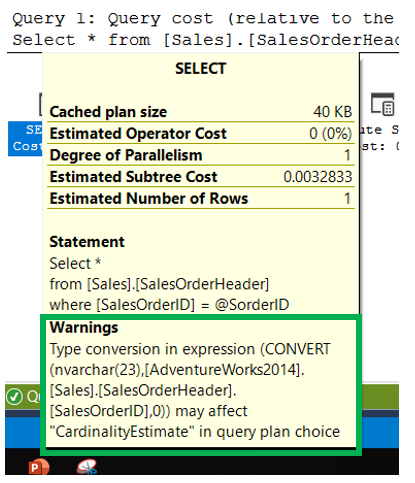
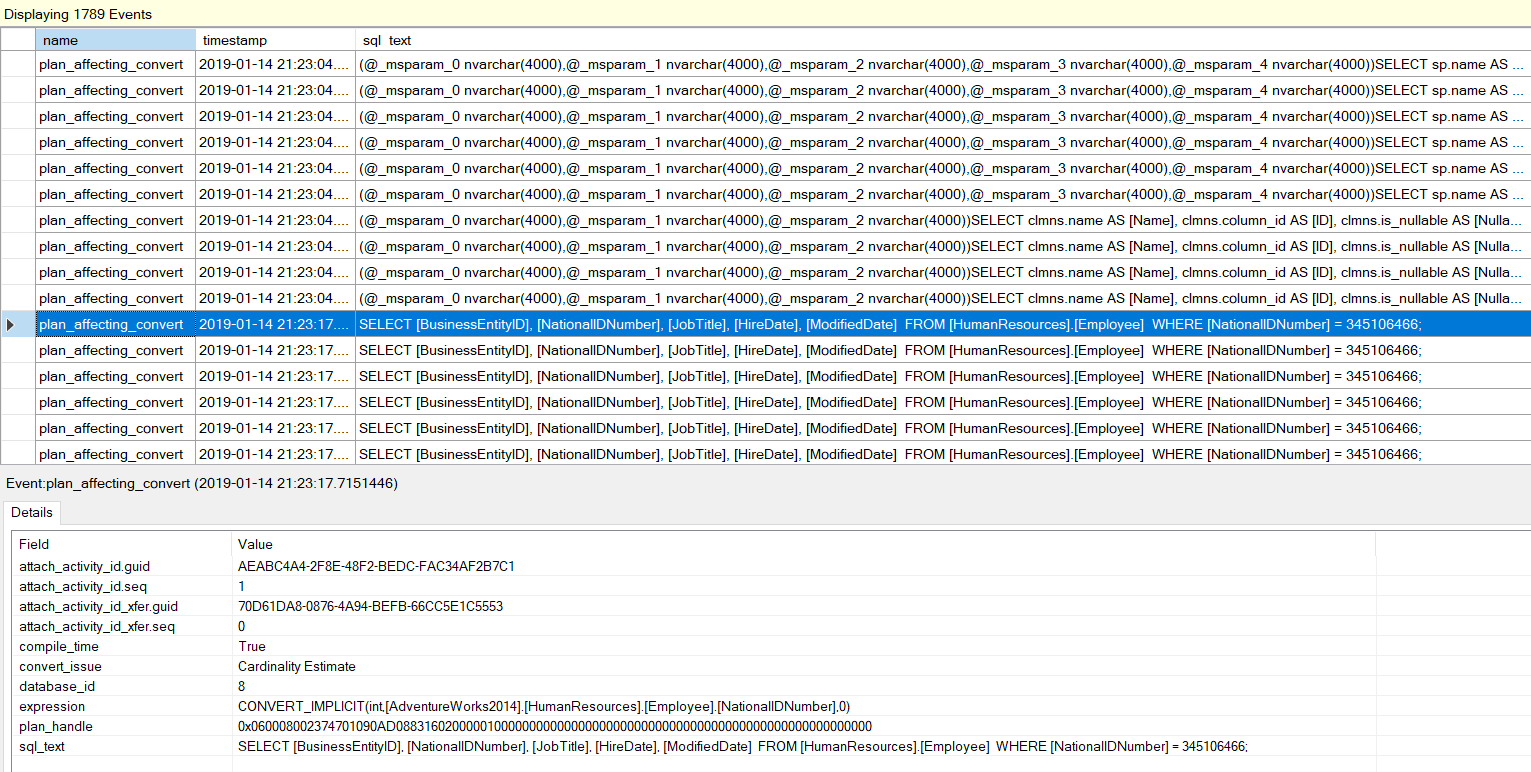
We recently received a number of calls(just one really), that when the user tried to execute their query they get an error. That error says the Global Temp Table Already Exists. We thought this should not be happening, so we sent our reports in to investigate. Their story is below.
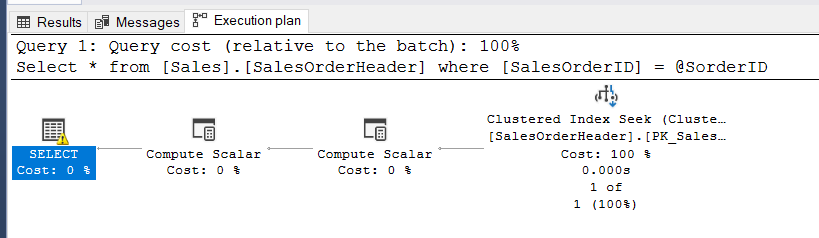
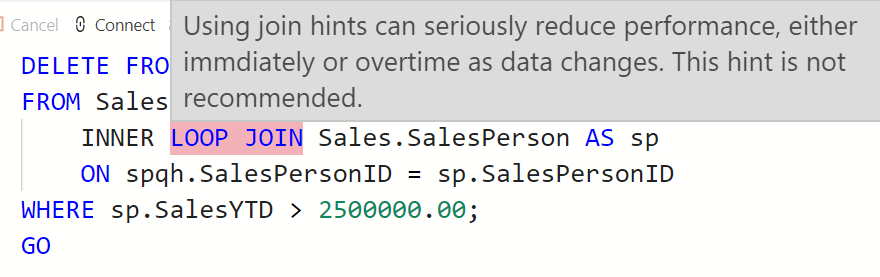
Before we get started, we should take a quick look at the error.

In order to understand the situation, we will need to figure out what a temp table is. As it’s name implies, it is a table that is temporary that is stored in the TempDB. There are two types in SQL Server, Local and Global. Phil Factor at Red Gate Simple Talk has some great definitions.
Local – As defined by Phil Factor at Red Gate Simple Talk – “With Local temporary table (names that begin with #), what goes on under the hood is surprisingly similar to table variables. Local Temporary tables are private to the process that created it. They cannot therefore be used in views and you cannot associate triggers with them.”
Global – Also as defined by Phil Factor at Red Gate Simple Talk – “Like Local temporary tables, Global temporary tables (they begin with ##) are automatically dropped when the session that created the table ends: However, because global tables aren’t private to the process that created it, they must persist thereafter until the last Transact-SQL statement that was actively referencing the table at the time when the creating session ended has finished executing and the locks are dropped.”
To find the culprit, we tracked down an old informant named sp_who2. At first he had no comment, but we knew he had some information that could help us, so we kept after him. Finally, he grew tired of us and gave us something just to make us go away. He said we needed to talk to his associate sysproccesses. At first this guy was hard to find, but we located him sitting at a table. He wasn’t really doing anything, just sitting there. So we approached him and sat down to see if we can get what we are looking for. He also had no comment and referred us to his lawyer, sys.dm_exec_sessions. After some searching, we were able to catch up with him at the DMV and he was not in a good mood. He gave up some information, just not exactly what we are looking for.
After all this, we still didn’t have answers to our most troubling questions.
Who created the object?
What code were they running when the object was created?
What database they using?
When was it created?
We were suspicious because sp_who2, sysprocesses and sys.dm_exec_sessions all gave us similar information, but different enough to make us suspect they were hiding something or protecting who really had the information.
So we decided to get tough. We had to interrogate the Tempdb. But we were at a dead end on how to go about doing it. Then out of the blue we received several useful tips.
Each had a different return address. They looked really good so we checked them out. The addresses are below.
https://www.c-sharpcorner.com/blogs/monitoring-tempdb-space-usage-on-sqlserver
http://kushagrarakesh.blogspot.com/2018/02/which-sessions-sql-text-cosuming-most.html
https://www.sqlservercentral.com/forums/topic/high-tempdb-usage-where-is-the-culprit
Despite the different addresses all the tips had the same message. This is what they said. Note: I did remove a bunch of columns that were not needed for what we are looking for.
They said run this.
SELECT R1.session_id
FROM (SELECT session_id
, request_id
, SUM(internal_objects_alloc_page_count) AS Task_request_internal_objects_alloc_page_count
, SUM(internal_objects_dealloc_page_count)AS Task_request_internal_objects_dealloc_page_count
, SUM(user_objects_alloc_page_count) AS Task_request_user_objects_alloc_page_count
, SUM(user_objects_dealloc_page_count)AS Task_request_user_objects_dealloc_page_count
FROM sys.dm_db_task_space_usage
GROUP BY session_id, request_id) R1
INNER JOIN (SELECT session_id
, SUM(internal_objects_alloc_page_count) AS Session_request_internal_objects_alloc_page_count
, SUM(internal_objects_dealloc_page_count)AS Session_request_internal_objects_dealloc_page_count
, SUM(user_objects_alloc_page_count) AS Session_request_user_objects_alloc_page_count
, SUM(user_objects_dealloc_page_count)AS Session_request_user_objects_dealloc_page_count
FROM sys.dm_db_Session_space_usage
GROUP BY session_id) R3
ON R1.session_id = R3.session_id
LEFT OUTER JOIN sys.dm_exec_requests R2
ON R1.session_id = R2.session_id
AND R1.request_id = R2.request_id
OUTER APPLY sys.dm_exec_sql_text(R2.sql_handle) AS RL2
WHERE
Task_request_internal_objects_alloc_page_count > 0 OR
Task_request_internal_objects_dealloc_page_count> 0 OR
Task_request_user_objects_alloc_page_count > 0 OR
Task_request_user_objects_dealloc_page_count > 0 OR
Session_request_internal_objects_alloc_page_count > 0 OR
Session_request_internal_objects_dealloc_page_count > 0 OR
Session_request_user_objects_alloc_page_count > 0 OR
Session_request_user_objects_dealloc_page_count > 0
We thought, what do we have to lose. So we used the proper amount of caution when running code in production and we ran it. After we did, we now felt like were were getting somewhere.
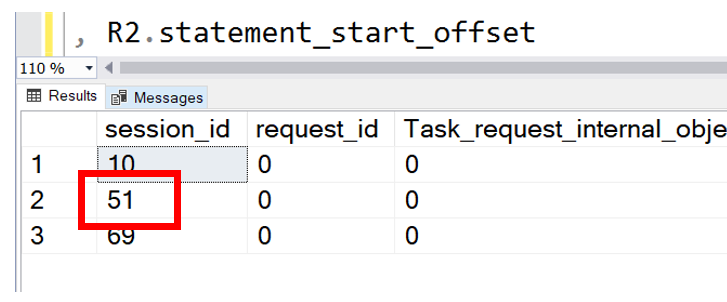
When we ran the above code our results looked similar to what you see below. The highlighted session_id is the session we are looking for.
Although we have found the SPiD, we still need an answer to a key question.
Who created the object?
To get this we can go back to our old friend, sp_who2. This time, we will be a bit tougher and lay it all on the table. We said we have evidence he knows who is running the query, we just need a name.
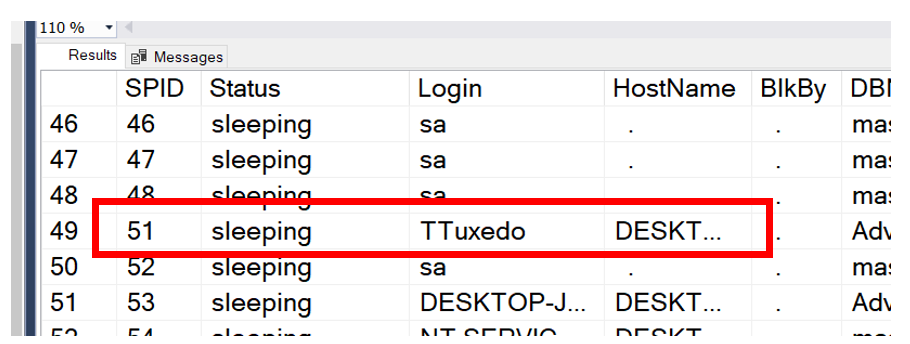
Since we had the SPID, we can use that to find out who is running the query. With sp_who2, we have not only identified who created the global temporary table, but we have also found out the host the user was using. What we learned is that we can get the name of who created the table several different ways. One is sp_who2, the other is to take the code above and add sysprocesses to the query.
SELECT R1.session_id
, p.uid AS ‘UserName’
FROM (SELECT session_id
, request_id
, SUM(internal_objects_alloc_page_count) AS Task_request_internal_objects_alloc_page_count
, SUM(internal_objects_dealloc_page_count)AS Task_request_internal_objects_dealloc_page_count
, SUM(user_objects_alloc_page_count) AS Task_request_user_objects_alloc_page_count
, SUM(user_objects_dealloc_page_count)AS Task_request_user_objects_dealloc_page_count
FROM sys.dm_db_task_space_usage
GROUP BY session_id, request_id) R1
INNER JOIN (SELECT session_id
, SUM(internal_objects_alloc_page_count) AS Session_request_internal_objects_alloc_page_count
, SUM(internal_objects_dealloc_page_count)AS Session_request_internal_objects_dealloc_page_count
, SUM(user_objects_alloc_page_count) AS Session_request_user_objects_alloc_page_count
, SUM(user_objects_dealloc_page_count)AS Session_request_user_objects_dealloc_page_count
FROM sys.dm_db_Session_space_usage
GROUP BY session_id) R3
ON R1.session_id = R3.session_id
INNER JOIN sysprocesses p
ON r1.session_ID = p.spid
LEFT OUTER JOIN sys.dm_exec_requests R2
ON R1.session_id = R2.session_id
AND R1.request_id = R2.request_id
OUTER APPLY sys.dm_exec_sql_text(R2.sql_handle) AS RL2
WHERE
Task_request_internal_objects_alloc_page_count > 0 OR
Task_request_internal_objects_dealloc_page_count> 0 OR
Task_request_user_objects_alloc_page_count > 0 OR
Task_request_user_objects_dealloc_page_count > 0 OR
Session_request_internal_objects_alloc_page_count > 0 OR
Session_request_internal_objects_dealloc_page_count > 0 OR
Session_request_user_objects_alloc_page_count > 0 OR
Session_request_user_objects_dealloc_page_count > 0
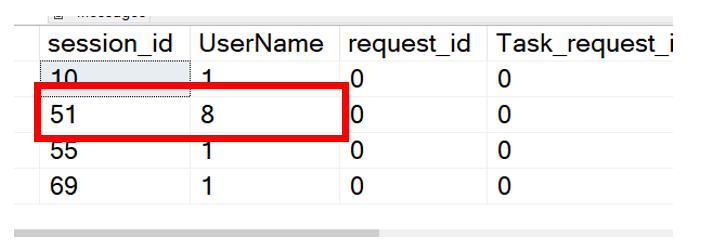
If you look at the code above, the text in red is what we added. When we run it, finally we are one step closer. We have the User ID. In this case it is 8.
However, we still need a name. Seems no one wants to give us a name besides sp_who2. However, using sp_who2 requires us to add a step to our investigative process. We are hoping it get all the information in one step. We had a trick up our sleeves, USER_NAME(). USER_NAME() knows everyone and we are sure he can help us out. This is great, however sometimes, things just don’t go as planned. We were still missing. If we run the query and we are connected to the wrong database we could get no name or even worst, an incorrect name. Below is an example of what you might see if connected to the incorrect database.
![]()
To remove the dependency of being in the database the object was created in we need to go back to sysprocesses. There is a column named sid. This is the security identifier of the login. The column looks like the image below.
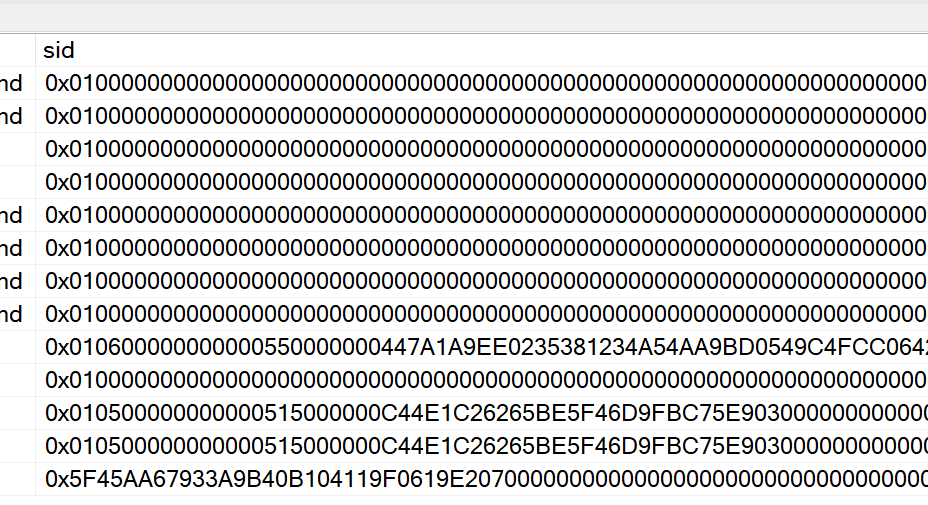
We were asking ourselves, how do we use this information to get the name. Well, this is where another object comes into play, syslogins. Syslogins table is where information about the logins is stored, included the SID. Since we already have sysprocesses in our query, we just need to add syslogins to our query. What was added is highlighted in red below.
—-The foundation for this code can be found at all of the links below
—-https://www.c-sharpcorner.com/blogs/monitoring-tempdb-space-usage-on-sqlserver
—-http://kushagrarakesh.blogspot.com/2018/02/which-sessions-sql-text-cosuming-most.html
—-https://www.sqlservercentral.com/forums/topic/high-tempdb-usage-where-is-the-culprit
SELECT R1.session_id AS ‘SPiD’
, lg.name AS ‘UserName’
, ib.event_info AS ‘Query’
FROM (SELECT session_id
, request_id
, SUM(internal_objects_alloc_page_count) AS Task_request_internal_objects_alloc_page_count
, SUM(internal_objects_dealloc_page_count)AS Task_request_internal_objects_dealloc_page_count
, SUM(user_objects_alloc_page_count) AS Task_request_user_objects_alloc_page_count
, SUM(user_objects_dealloc_page_count)AS Task_request_user_objects_dealloc_page_count
FROM sys.dm_db_task_space_usage
WHERE session_id > 50
GROUP BY session_id, request_id) R1
INNER JOIN (SELECT session_id
, SUM(internal_objects_alloc_page_count) AS Session_request_internal_objects_alloc_page_count
, SUM(internal_objects_dealloc_page_count)AS Session_request_internal_objects_dealloc_page_count
, SUM(user_objects_alloc_page_count) AS Session_request_user_objects_alloc_page_count
, SUM(user_objects_dealloc_page_count)AS Session_request_user_objects_dealloc_page_count
FROM sys.dm_db_Session_space_usage
GROUP BY session_id) R3
ON R1.session_id = R3.session_id
INNER JOIN sysprocesses pr
ON r1.session_ID = pr.spid
INNER JOIN sysdatabases db
ON pr.dbid = db.dbid
INNER JOIN syslogins lg
ON lg.sid = pr.sid
CROSS APPLY sys.dm_exec_input_buffer(R1.session_id,null) ib
WHERE
Task_request_internal_objects_alloc_page_count > 0 OR
Task_request_internal_objects_dealloc_page_count> 0 OR
Task_request_user_objects_alloc_page_count > 0 OR
Task_request_user_objects_dealloc_page_count > 0 OR
Session_request_internal_objects_alloc_page_count > 0 OR
Session_request_internal_objects_dealloc_page_count > 0 OR
Session_request_user_objects_alloc_page_count > 0 OR
Session_request_user_objects_dealloc_page_count > 0
We are almost there. We currently know the SPiD and User Name We still need to get the code and we would also like to get the database name as well. To get that we will need to get back to sysprocesses. When we run it we find the spid column from sysprocesses. This will give us what database ID we need to use. The name of the column is dbid.
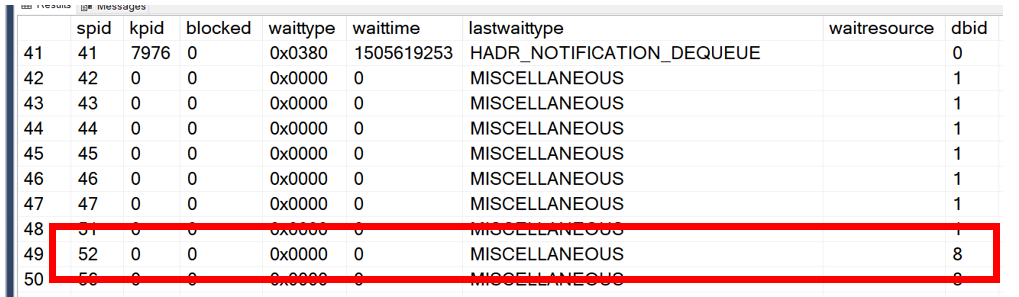
However, I really need the name of the database. Sysdatabases is going to be our friend to get the name of the database. We want to join on the dbid column. This addition is highlighted with red text below.
—-The foundation for this code can be found at all of the links below
—-https://www.c-sharpcorner.com/blogs/monitoring-tempdb-space-usage-on-sqlserver
—-http://kushagrarakesh.blogspot.com/2018/02/which-sessions-sql-text-cosuming-most.html
—-https://www.sqlservercentral.com/forums/topic/high-tempdb-usage-where-is-the-culprit
SELECT R1.session_id AS ‘SPiD’
, db.name
, lg.name AS ‘UserName’
, ib.event_info AS ‘Query’
FROM (SELECT session_id
, request_id
, SUM(internal_objects_alloc_page_count) AS Task_request_internal_objects_alloc_page_count
, SUM(internal_objects_dealloc_page_count)AS Task_request_internal_objects_dealloc_page_count
, SUM(user_objects_alloc_page_count) AS Task_request_user_objects_alloc_page_count
, SUM(user_objects_dealloc_page_count)AS Task_request_user_objects_dealloc_page_count
FROM sys.dm_db_task_space_usage
WHERE session_id > 50
GROUP BY session_id, request_id) R1
INNER JOIN (SELECT session_id
, SUM(internal_objects_alloc_page_count) AS Session_request_internal_objects_alloc_page_count
, SUM(internal_objects_dealloc_page_count)AS Session_request_internal_objects_dealloc_page_count
, SUM(user_objects_alloc_page_count) AS Session_request_user_objects_alloc_page_count
, SUM(user_objects_dealloc_page_count)AS Session_request_user_objects_dealloc_page_count
FROM sys.dm_db_Session_space_usage
GROUP BY session_id) R3
ON R1.session_id = R3.session_id
INNER JOIN sysprocesses pr
ON r1.session_ID = pr.spid
INNER JOIN sysdatabases db
ON pr.dbid = db.dbid
INNER JOIN syslogins lg
ON lg.sid = pr.sid
CROSS APPLY sys.dm_exec_input_buffer(R1.session_id,null) ib
WHERE
Task_request_internal_objects_alloc_page_count > 0 OR
Task_request_internal_objects_dealloc_page_count> 0 OR
Task_request_user_objects_alloc_page_count > 0 OR
Task_request_user_objects_dealloc_page_count > 0 OR
Session_request_internal_objects_alloc_page_count > 0 OR
Session_request_internal_objects_dealloc_page_count > 0 OR
Session_request_user_objects_alloc_page_count > 0 OR
Session_request_user_objects_dealloc_page_count > 0
We now know who created the temp table and what database they are using. We feel like we are on a roll in our investigation, however we are not done yet. The last bit of information we need is what query is this person running. To get this we have a few choices. We had a number of volunteers offering to assist. One has been around for a while and we have used as in informant many times in the past. While the other just moved in to the neighborhood a few years ago.
The one that have been around for a while are DBCC INPUTBUFFER.
This is what we ran with INPUTBUFFER.
DBCC INPUTBUFFER(52)
The results are below.

While he did give us what we are looking for, we again have have multiple steps to run through to get what we are looking for. He also doesn’t work well with others, he doesn’t join like we would like him to. We were looking for someone that can work well with others so we can only ask the questions one time and in one step. We recently heard about a new kid on the block that moved in a few years ago, SQL Server 2014 sp2 to be exact. His name is sys.dm_exec_input_buffer. He said he has worked with sysprocesses before and they work well together. So we decided to give him a shot.
—-The foundation for this code can be found at all of the links below
—-https://www.c-sharpcorner.com/blogs/monitoring-tempdb-space-usage-on-sqlserver
—-http://kushagrarakesh.blogspot.com/2018/02/which-sessions-sql-text-cosuming-most.html
—-https://www.sqlservercentral.com/forums/topic/high-tempdb-usage-where-is-the-culprit
SELECT R1.session_id AS ‘SPiD’
, db.name
, lg.name AS ‘UserName’
, ib.event_info AS ‘Query’
FROM (SELECT session_id
, request_id
, SUM(internal_objects_alloc_page_count) AS Task_request_internal_objects_alloc_page_count
, SUM(internal_objects_dealloc_page_count)AS Task_request_internal_objects_dealloc_page_count
, SUM(user_objects_alloc_page_count) AS Task_request_user_objects_alloc_page_count
, SUM(user_objects_dealloc_page_count)AS Task_request_user_objects_dealloc_page_count
FROM sys.dm_db_task_space_usage
WHERE session_id > 50
GROUP BY session_id, request_id) R1
INNER JOIN (SELECT session_id
, SUM(internal_objects_alloc_page_count) AS Session_request_internal_objects_alloc_page_count
, SUM(internal_objects_dealloc_page_count)AS Session_request_internal_objects_dealloc_page_count
, SUM(user_objects_alloc_page_count) AS Session_request_user_objects_alloc_page_count
, SUM(user_objects_dealloc_page_count)AS Session_request_user_objects_dealloc_page_count
FROM sys.dm_db_Session_space_usage
GROUP BY session_id) R3
ON R1.session_id = R3.session_id
INNER JOIN sysprocesses pr
ON r1.session_ID = pr.spid
INNER JOIN sysdatabases db
ON pr.dbid = db.dbid
INNER JOIN syslogins lg
ON lg.sid = pr.sid
CROSS APPLY sys.dm_exec_input_buffer(R1.session_id,null) ib
WHERE
Task_request_internal_objects_alloc_page_count > 0 OR
Task_request_internal_objects_dealloc_page_count> 0 OR
Task_request_user_objects_alloc_page_count > 0 OR
Task_request_user_objects_dealloc_page_count > 0 OR
Session_request_internal_objects_alloc_page_count > 0 OR
Session_request_internal_objects_dealloc_page_count > 0 OR
Session_request_user_objects_alloc_page_count > 0 OR
Session_request_user_objects_dealloc_page_count > 0
We had to modify the code one more time. The additions are above in red. We finally have everything we need!

Our goal was to answer some question.
Who created the object?
Answer: TTuxedo
What were they running when the object was created?
Answer: Create table ##mytable (myname varchar(129)) Insert ##mytable(MyName) Values(‘Dave’)
When was it created?
Answer: Don’t have the answer to this yet.
To find out when the object was created, we have to use another query. This time we need to go directly to the TempDB using the sysobjects table. We will need to search on the object name using a wildcard.
SELECT name
, crdate
FROM tempdb.dbo.sysobjects
WHERE name LIKE ‘#%’
This is what the results will look like. Now was have the answer to the final question. While this is a nice to have, it wasn’t one of the original requirements. With this, we are OK with it being an additional step.

We now have everything we need to conclude our investigation. If you look below, you will see the database name, User Name and the query that was used to create the object.

Now we will need to determine the next steps. Do we need to dig deeper? Do we let the query finish? Do we terminate the process? In this case, we dug a bit deeper and found that someone ran someone ran some code that created the temp table and didn’t close the connection. Because of this, the temp table stuck around much longer than needed creating a situation that led to the error mentioned at the beginning of this post.
So let’s summarize what objects were used to solve this problem.
To Find the Temporary objects
sys.dm_db_task_space_usage
To get the User Name and Database Name
Syslogins and SysDatabases
To get the query
sys.dm_exec_input_buffer
Here is the final block of code. You can run this in any database.
—-The foundation for this code can be found at all of the links below
—-https://www.c-sharpcorner.com/blogs/monitoring-tempdb-space-usage-on-sqlserver
—-http://kushagrarakesh.blogspot.com/2018/02/which-sessions-sql-text-cosuming-most.html
—-https://www.sqlservercentral.com/forums/topic/high-tempdb-usage-where-is-the-culprit
SELECT R1.session_id AS ‘SPiD’
, db.name
, lg.name AS ‘UserName’
, ib.event_info AS ‘Query’
FROM (SELECT session_id
, request_id
, SUM(internal_objects_alloc_page_count) AS ‘Task_request_internal_objects_alloc_page_count’
, SUM(internal_objects_dealloc_page_count)AS ‘Task_request_internal_objects_dealloc_page_count’
, SUM(user_objects_alloc_page_count) AS ‘Task_request_user_objects_alloc_page_count’
, SUM(user_objects_dealloc_page_count)AS ‘Task_request_user_objects_dealloc_page_count’
FROM sys.dm_db_task_space_usage
WHERE session_id > 50
GROUP BY session_id, request_id) R1
INNER JOIN (SELECT session_id
, SUM(internal_objects_alloc_page_count) AS ‘Session_request_internal_objects_alloc_page_count’
, SUM(internal_objects_dealloc_page_count)AS ‘Session_request_internal_objects_dealloc_page_count’
, SUM(user_objects_alloc_page_count) AS ‘Session_request_user_objects_alloc_page_count’
, SUM(user_objects_dealloc_page_count)AS ‘Session_request_user_objects_dealloc_page_count’
FROM sys.dm_db_Session_space_usage
GROUP BY session_id) R3
ON R1.session_id = R3.session_id
INNER JOIN sysprocesses pr
ON r1.session_ID = pr.spid
INNER JOIN sysdatabases db
ON pr.dbid = db.dbid
INNER JOIN syslogins lg
ON lg.sid = pr.sid
CROSS APPLY sys.dm_exec_input_buffer(R1.session_id,null) ib
WHERE
Task_request_internal_objects_alloc_page_count > 0 OR
Task_request_internal_objects_dealloc_page_count> 0 OR
Task_request_user_objects_alloc_page_count > 0 OR
Task_request_user_objects_dealloc_page_count > 0 OR
Session_request_internal_objects_alloc_page_count > 0 OR
Session_request_internal_objects_dealloc_page_count > 0 OR
Session_request_user_objects_alloc_page_count > 0 OR
Session_request_user_objects_dealloc_page_count > 0
For our final report I used Data Tools to create and SSRS report that can be used in SQL Server Management Studio. It looks like the image below. You can also down load the RDL file here: WhoCreatedTempObjects

Our investigative team has found the problem code and solved the issue. Now back to YouTube. For this post I wanted to try something a bit different, make a story out of it. Hopefully, you still learned something. That is why I do this, to help others learn.
Thanks for visiting my blog.
 You do not need to restart Azure Data Studio to see the new group in the Connections pane. However, you will need to restart SQL Server Management Studio to see the new group in the Registered Servers window.
You do not need to restart Azure Data Studio to see the new group in the Connections pane. However, you will need to restart SQL Server Management Studio to see the new group in the Registered Servers window.