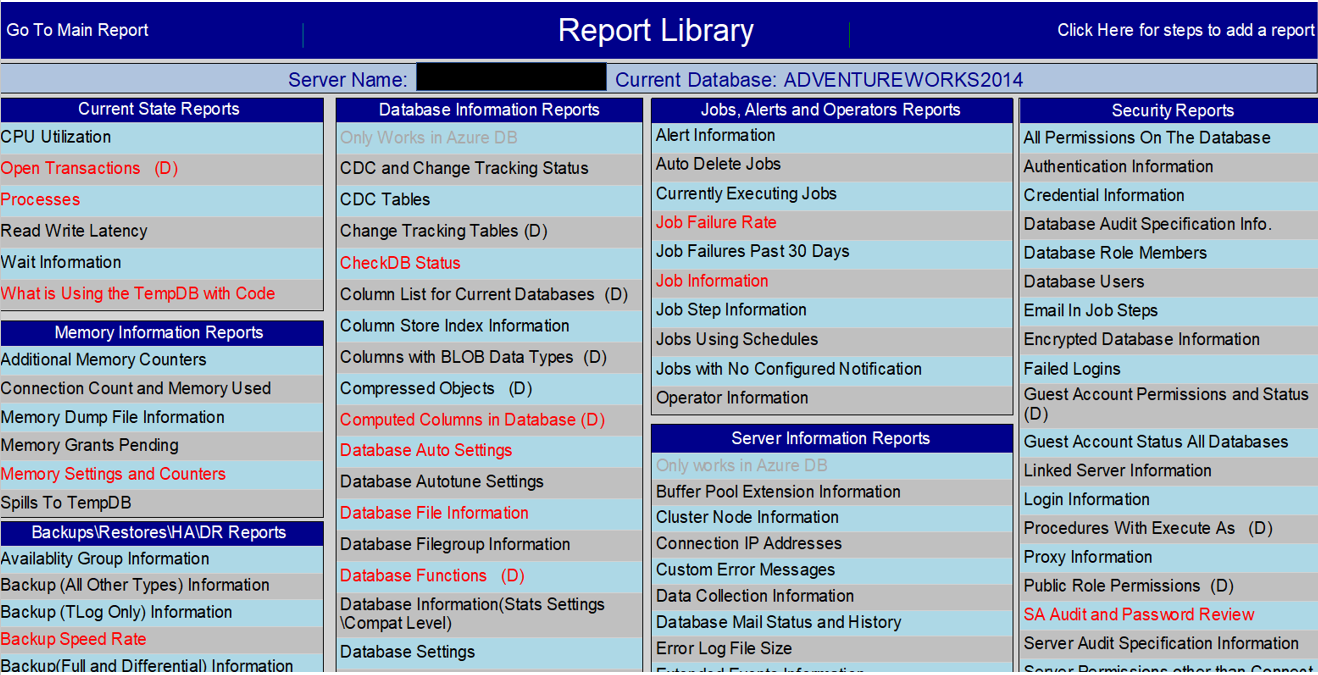
| Report Name |
Purpose Of The Report |
| Additional Memory Counters |
More memory related counters such as Free List Stalls and Lazy Writes |
| Alert Information |
General information about the Alerts, including the last occurence. |
| All Permissions On The Database |
Returns the permissions on the database. This excludes the system database roles, the Public role and the Guest account |
| Authentication Information |
Windows or Mixed authentication. How is the server configured? |
| Auto Delete Jobs |
Are there any jobs configured to delete automatically? This report will tell you. |
| Availability Group Information |
What Availability Groups exist and what databases are involved |
| Azure Database Resource Stats |
Returns Performance related information on an Azure SQL DB |
| Azure SQL DB Service Tiers |
You can use this report to find the service level for each Azure SQL DB on your instance. |
| Backup (All Other Types) Information |
History of all other types of backups |
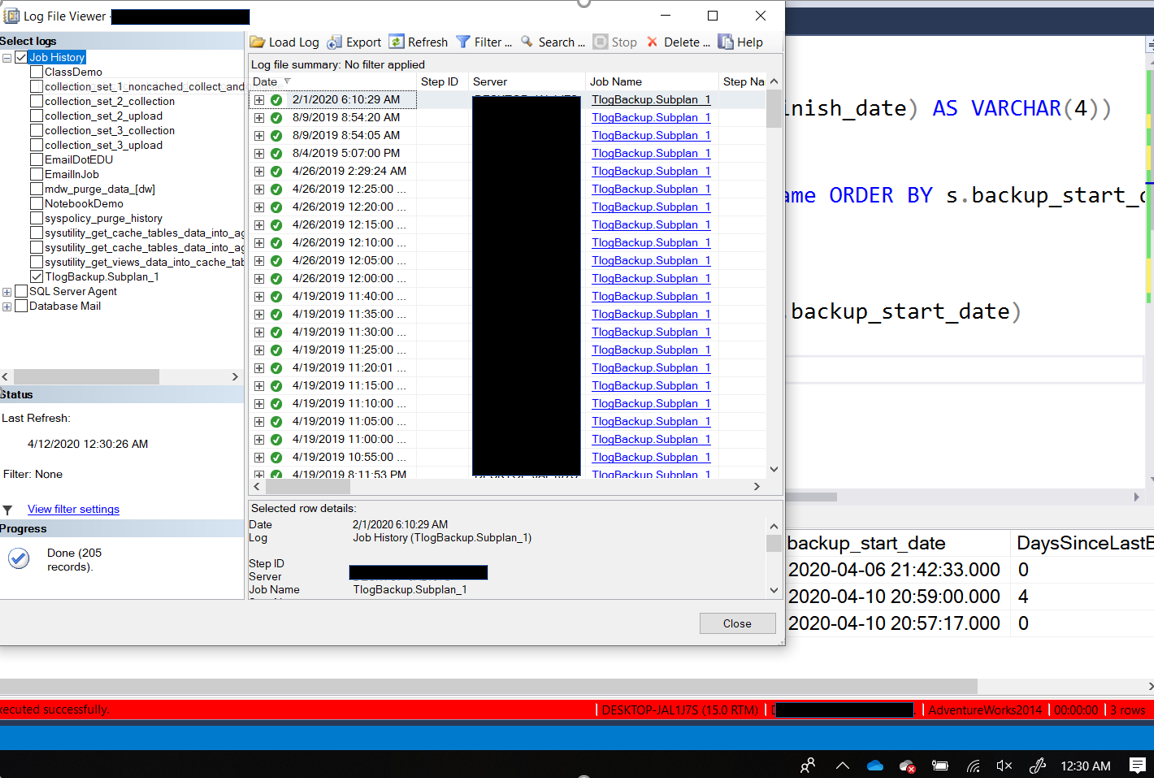
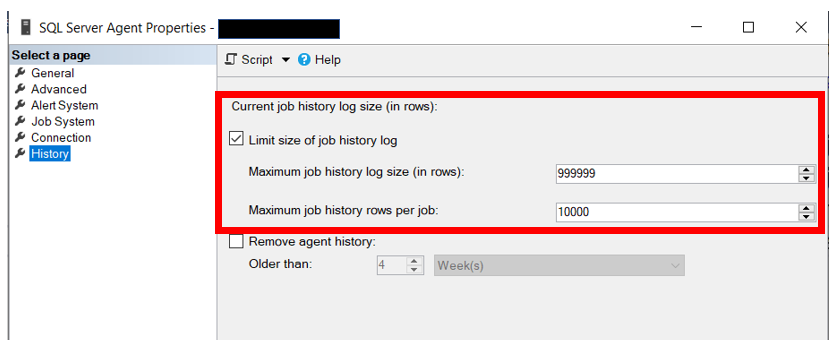
| Backup (TLog Only) Information |
History of transaction log backups |
| Backup Speed Rate |
The MB\Sec for each backup |
| Backup(Full and Differential) Information |
History of Full and Differential backups, including the device backed up to |
| Buffer Pool Extension Information |
Returns the file path, size and number of pages in the bufferpool extension |
| CDC and Change Tracking Status |
Returns the status of CDC and Change Tracking |
| CDC Tables |
What tables are using Change Data Capture |
| Change Tracking Tables (D) |
What tables are configured for Change Tracking |
| CheckDB Status |
Returns the date of the last successful CheckDB |
| Cluster Node Information |
Is the server in a cluster? |
| Column List for Current Databases (D) |
Simple list of all the columns in each table |
| Column Store Index Information |
Returns information about the Column Store indexes includes type, size and row count |
| Columns with BLOB data types |
Lists all columns in the current database that use XML, VARCHAR(MAX), NVARCHAR(MAX), VARBINARY(MAX), IMAGE and TEXT data types |
| Compressed Objects (D) |
Compression status of each object |
| Computed Columns in Database (D) |
Location and definition of each computed column in the current database |
| Connection Count and Memory Used |
Many connections to the server and how much memory is being consumed |
| Connection IP Addresses |
IP addresses of existing connections |
| CPU Utilization |
CPU Utilization by minute for the last few days. Returns CPU usage for both “SQL Server” and “Other Processes” |
| Credential Information |
Are there any credentials on the server? |
| Currently Running Jobs |
What jobs are currently running. |
| Custom Error Messages |
Looks for custom error messages, anything with a number above 50,000 |
| Database Audit Specification Information |
Database Audit information, including what Server Audit each is using |
| Database Auto Settings |
Returns setting status for “Auto Update Stats”, “Auto Create Stats” and a few others |
| Database Auto Tune Settings |
Returns current status of the Auto Tune settings |
| Database File Information |
Location of each database related file |
| Database Filegroup Information |
Filegroup information for each database |
| Database Functions (D) |
Any user defined functions? |
| Database Information(Stats Settings\Compat Level) |
Compatibility level and addition settings for each database |
| Database Mail Status and History |
Returns information about the history of database mail, including who it was sent to |
| Database Role Members |
Returns the members of each database role for all the databases |
| Database Settings |
Settings on the databases that might be useful to know |
| Database Snapshot Information |
Are there any snapshots? |
| Database Triggers (D) |
Find those hidden triggers with this report |
| Database Users |
Who is in what databases |
| Database Virtual Log Files |
Virtual Log File count for each database. Will provide a warn if the count is too high |
| Databases Not in Offline\Online State |
State of each database is on Offline or Online |
| Default Constraint Info. (D) |
Default constraints and where they are being used |
| Duplicate Indexes |
Returns all indexes that have a duplicate on the same table |
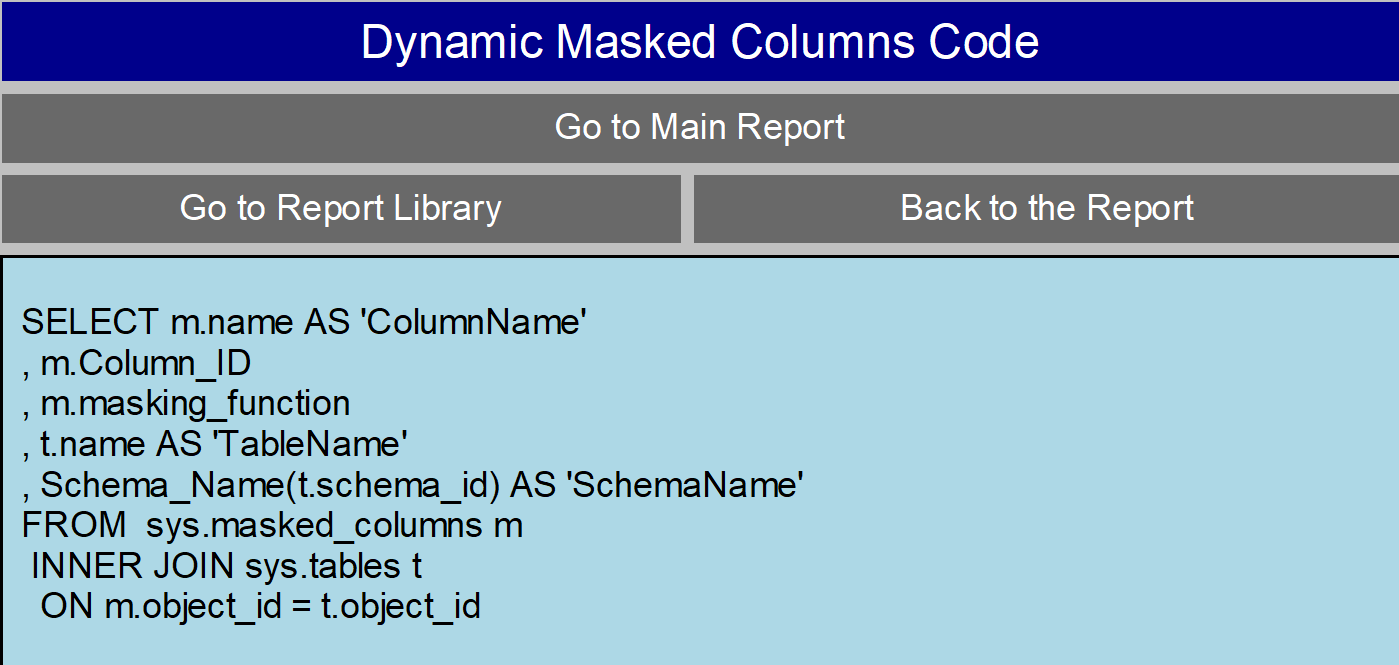
| Dynamic Masked Columns |
Lists the columns that are masked |
| Email In Job Steps |
Email addresses found in job steps. |
| Enabled Trace Flags |
Currently enabled trace flags |
| Encrypted Database Information |
Any encrypted databases? |
| Error Log File Size |
Returns the size of each of the archived error log files, as well as the current error log |
| Extended Events Information |
What Extended Event Sessions exist |
| Extended Events Session Status |
Returns the running status for each of the Exended Event sessions |
| Failed Logins |
What failed logins are happening. Only looks at the current log |
| File Size\Space Used |
The name, size and free space of each file for all the databases. |
| Forwarded Records (D) |
The number of forwarded records since the service was last started and the number of forwarded records in tables |
| Full Text Index Info. (D) |
Full text indexes….are there any? |
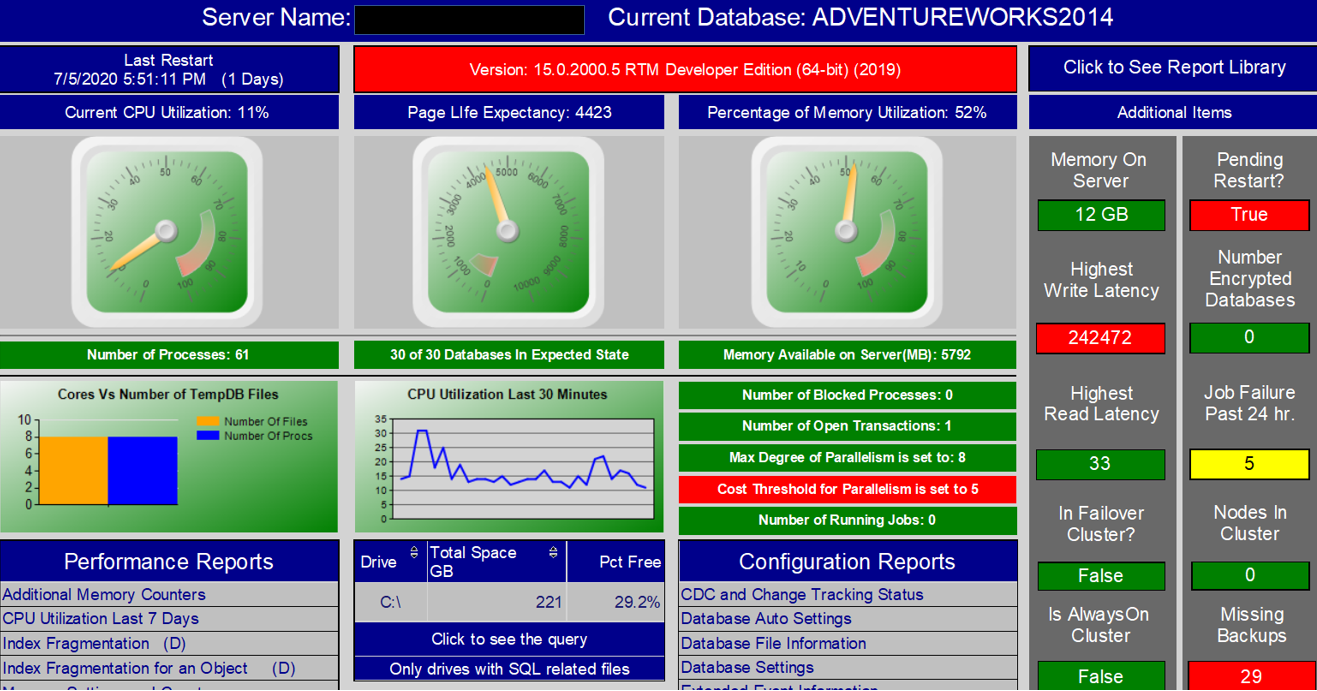
| General Information |
General information about the SQL Server and Windows Server |
| Guest Account Permissions and Status (D) |
Status of the Guest account for the current database |
| Guest Account Status All Databases |
Status of the Guest account for each database |
| Index Fragmentation (D) |
Index fragmentation percentage |
| Index Fragmentation for an Object (D) |
This is the code if you want to check the fragmentation of indexes on a specific object |
| Index Information (D) |
Name, type and location of each index in the database |
| Index To Column Ratio by Table (D) |
The ratio of Indexes to Columns. Could help us identify if there are too many indexes |
| Index Usage |
Returns user seeks, scans, lookups and updates for all indexes in the database |
| Indexes That are unused |
Returns indexes where there are not any user seeks, scans and lookups in the database |
| Job Failure Rate Past 90 Days |
This returns the percentage of failures for each job for the past 90 days. |
| Job Failures Last 30 Days |
Returns information about job failures for the past 30 days. |
| Job Information |
General information about each job, including schedules and notifications. |
| Job Step Information |
Provides some detail about each jobs step, including what type of step |
| Jobs Using Schedules |
What schedules are being used and what jobs are using them |
| Jobs with No Configured Notification |
If there are jobs that do not have any notifications configured, this report will help you find them. |
| Linked Server Information |
Information about all the linked servers, most importantly is it configured to use Self credentials |
| Log Shipping Databases |
Databases with log shipping configured |
| Login Information |
Information about each login on the server |
| Mail Configuration |
Information about the mail confiuration including profiles and mail servers |
| Mail Configuration Parameters |
Returns the parameter configuration for database mail |
| Memory Dump File Information |
Location, when created and size of each memory dump file. |
| Memory Grants Pending |
Returns the SPIDs with pending memory grants with the query |
| Memory Optimized Tables |
Returns information about all the memory optimized tables in all the databases. This also includes the allocated and used sizes |
| Memory Settings and Counters |
Configuration of important memory settings |
| Mirrored Database Information |
Mirrored Databases, do they exist? |
| Missing Backups |
Any database without a full backup in past few days or no log backup as well |
| Nonsargable Searches in Stored Procedures |
Returns the list of stored procedures that have Nonsargable searches. This include functions in the WHERE clause and leading wildcard searches |
| Objects with Schemabinding |
Returns a list of all the objects, with code, that have schemabinding |
| Open Transactions |
Information about open transactions on the server. |
| Operator Information |
Information about each operators, including email address |
| Orphan Database Users |
Returns database user accounts that do not have a matching login, either by SID or by name |
| Partitioned Tables |
Report on what tables are partitioned |
| Plan Guides |
Returns the query defined in the plan guide, if any exist |
| Plans In Cache with Implicit Convert |
Returns the TOP 100 query plans based on execution count that have an Implicit Convert |
| Procedures With Execute As (D) |
Returns any procedure that has the keywords “Execute As” in the definition |
| Processes |
Lists all the user processes and identifies blocking information. |
| Processor Information |
How many processors on the server? |
| Proxy Information |
General information about each proxy |
| Public Role Permissions (D) |
Permissions for the public role |
| Queries with High Logical Reads (D) |
Returns the top 10 queries based on the number of logical reads |
| Query Store Status and Settings |
Query store status |
| Read Write Latency |
Returns Read\Write latency for each file for all databases. This includes both data and log files. |
| Replication Information |
Any replication? |
| Restore Information |
Any restores of databases? |
| SA Audit and Password Review |
Will tell you if any accounts have security issues, passwords same as account name or no password. Will also return settings of the SA account |
| Security Policy Information |
Returns information about the security policies in the database |
| Server Audit Specification Information |
Server Audit information |
| Server Permissions other than Connect |
Logins that have permissions at the server level other than connect |
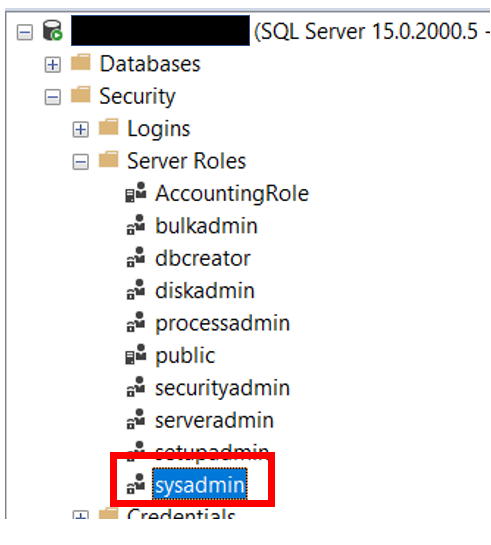
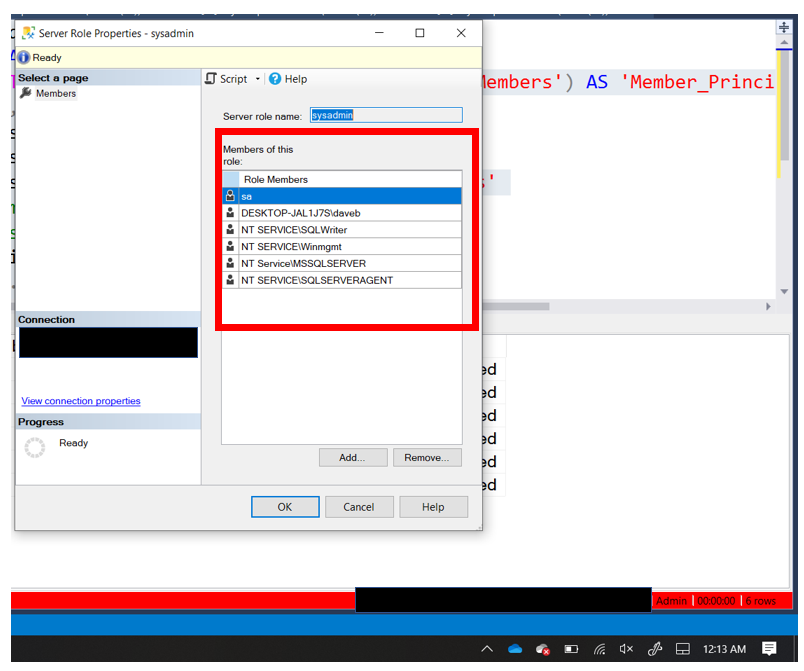
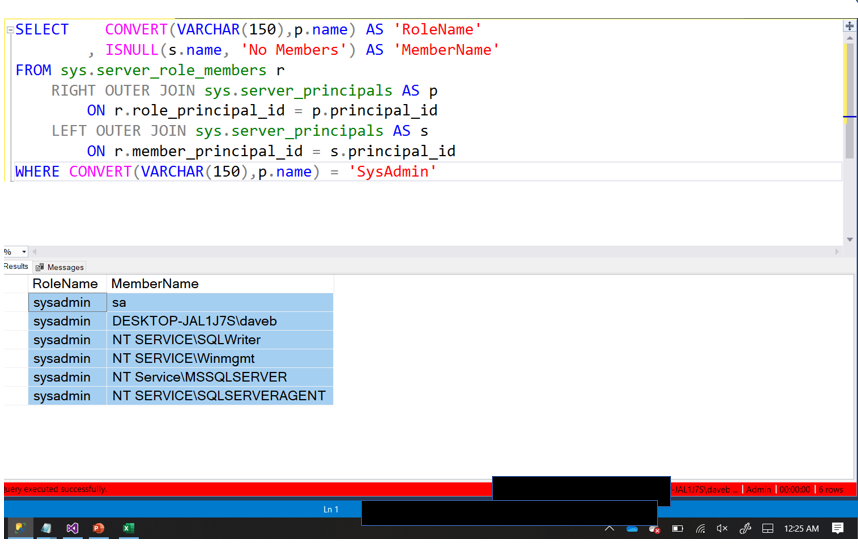
| Server Role Information and Membership |
Who is in each server role |
| Server Triggers |
Returns information about server triggers if any exist |
| Service Account Information |
What account is being used to run the services. Also will return the status of the service |
| Spills To TempDB |
Executes sys.dm_exec_query_stats to get the number of spills to TempDB for completed queries that still have a plan in the cache |
| Spinlock Information |
Returns information about spinlocks including backoffs |
| Start up Parameters |
Definition of each of the start up parameters |
| Statistics Information (D) |
Information about statistics, including last updated date, sample rate and modification counts |
| Stored Procedures that have a “Select *” |
Returns all stored procedures that have a “Select *” in the code somewhere |
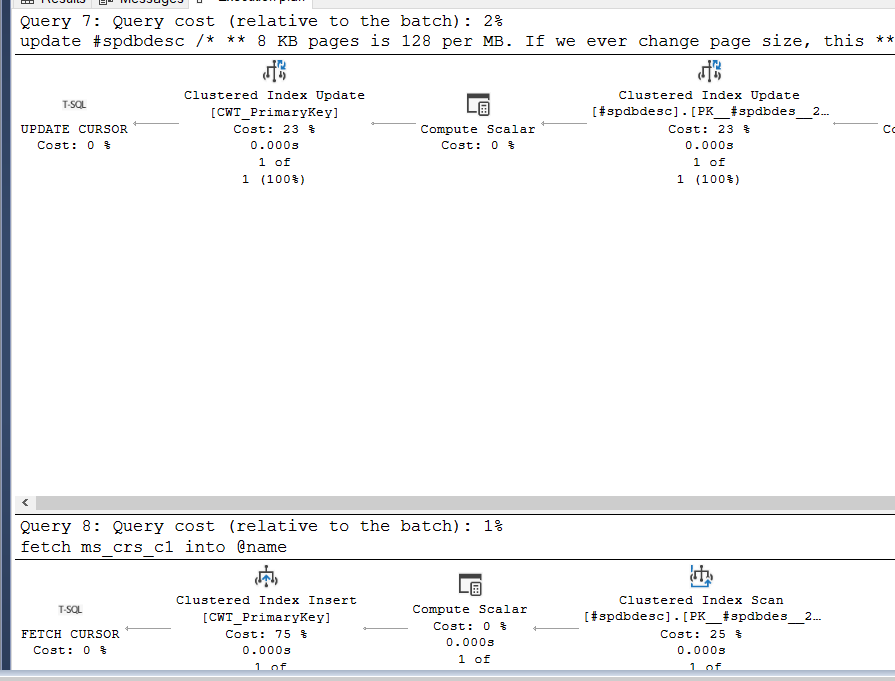
| Stored Procedures that have CURSOR” |
Returns all stored procedures that have a CURSOR in the code somewhere |
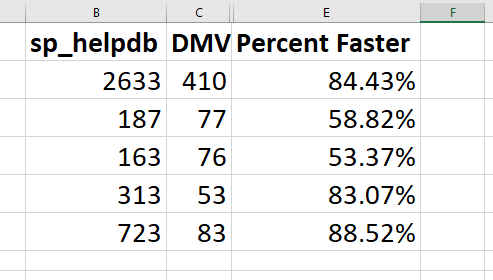
| Stored Procedures that start with SP_ |
Returns any stored procedure that starts with SP_. Proces with this naming convention can present issues if MS comes out with a proc of the same name. |
| Stored Procs Created or Modified Last 90 Days (D) |
Stored procs created or modified in past 90 days |
| Stored Procs with Deadlock Priority Set |
Returns the list of stord procedures that have the DEADLOCK_PRIORITY set |
| Stored Procs with NOCOUNT Set to OFF |
Returns the list of stord procedures that have NOCOUNT set to OFF or not set at all |
| Stored Procs with Recompile |
Returns all the stored procedures that have the keyword recompile in the definition |
| Stretch Database Information |
Returns information about the stretch tables in the database |
| Synonym Information (D) |
Checks for the presence of Synonyms and the definition of each |
| Sys.Configurations |
Returns the contents of the Configurations table. Will identify which settings are causing a pending reboot |
| Table Row Counts and Size (D) |
Returns row counts for all tables in the database as well as the size |
| Tables Created or Modified Last 90 Days (D) |
List of tables that were created or modified in the past 90 days |
| Tables That are Heaps (D) |
Where are those heaps….use this report to find them |
| TempDB Information |
How many files in the TempDB including file size |
| Temporal Table Information |
Returns all temporal tables as well as the create date and retention period |
| Trace Flags Being Used |
This report reviews the past three logs looking for any trace flag that was turned on. This does not return current status of enabled trace flags. |
| Trace Information |
Any traces running? |
| User Defined Data Type Usage |
Returns the columns the are using User Defined Datatypes |
| User Defined Data Types (D) |
What user defined database exist in the database and where are they used |
| Users DMLRights other than SELECT (D) |
Who can change data or object definition |
| Views Created or Modified Last 90 Days (D) |
Views created or modified in the past 90 days |
| Wait Information |
Information about some of the common important wait types. |
| What is Using the TempDB with Code |
Returns what processes are currently using the TempDB. |